Index
- Introduction to Statistics and Econometrics
- Simple Regression Analysis
- Multiple Regression Analysis: Basics
- Multiple Regression Analysis: Inference
- Multiple Regression Analysis: Further Issues
- Heteroskedasticity and Other Problems
- Time Series Data
- Panel Data
- Instrumental Variables
1 Introduction to Statistics and Econometrics
Econometrics is the use of statistical methods to analyze economic data, starting typically from non-experimental data.
- estimating relationships between variables
- testing economic theories and hypotheses
- evaluating and implementing government and business policy
Structure of Econometric Data
- Cross sectional data
- observations that represent individuals, firms, cantons, countries (normally, but not necessarily, at one point in time).
- observations are drawn randomly from a population (if not, we have a sample-selection problem)
- Time Series Data
- observations represent periods in time
- observations are consecutive and hence not random
- Pool Cross-Sections
- at least two cross sections are combined in one data set
- cross sections are drawn independently of each other
- can often be treated similar to a normal cross section
- Panel (or longitudinal data)
- cross-sectional units followed over time
- panel data have a cross-sectional and time series dimension
- useful to account for time-invariant unobservables and for modeling lagged responses
Causality
The definition of causal effect of on is: "how does variable change if variable is changed, but all other factors are held constant?
(This concept is called Ceteris Paribus).
Simply establishing a relationship (correlation) between variables can be misleading (important distinction between correlation and causation!)
There are multiple types of experiments that allow answering causal questions:
- Randomized controlled trials (RCT)
- Natural experiments
Probability Review: Distributions
- Chi-Square Distribution
Let be independent random variables with , then
has a chi-square distribution with degrees of freedom and we write .
- t-Distribution
Let and , then
has a t-distribution with degrees of freedom and we write .
- F-Distribution
Let and and assume independent, then:
has an F-distribution with degrees of freedom and we write .
Central Limit TheoremThe standardized average of any population with mean and variance is asymptotically distributed, or, in other words:
Law of Large NumbersLet be independent, identically distributed random variables with mean , then:
2 Simple Regression Analysis
How can we use the data to describe economic relations or behaviors?
- : dependent variable (outcome variable)
- : independent variable (regressor, covariate, control variable, "the cause")
- : error term (disturbance)
- it represents strictly unpredictable random behaviors, unspecified or unobserved factors or an approximation error if the relation is not perfectly linear.
- : intercept parameter
- : slope parameter
We start now with Population Modelling and consider the following assumptions:
-
SLR.1: Linear parameters
- in the population model the following relation holds:
-- SLR.2: Random sampling
-
we have a random sample of size of pairs
-
SLR.3: Sample variation in the explanatory variable
- the sample outcomes on are not all the same value
- SLR.4: Zero Conditional Mean
or, in other words, for every slice of the population determined by , the average of is equal to the population average (which is zero).
This also implies:
also called the Population Regression Function.
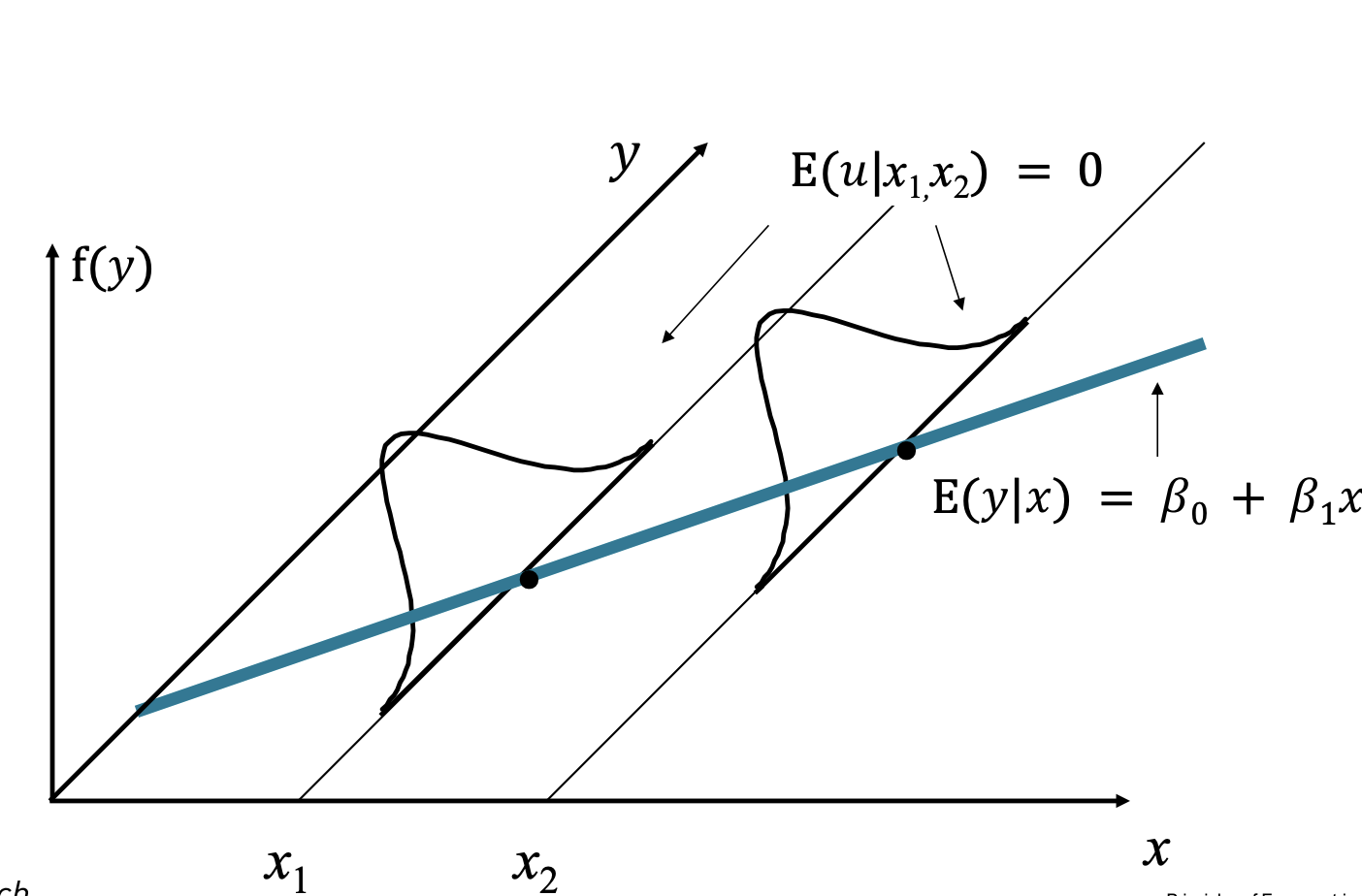
We now derive the Ordinary Least Squares (OLS).
Intuition: we estimate the population parameters from a data sample of two random variables.
- Let denote a random sample of size
- scatter plot in a system
- the regression equation allocates to each a value including a disturbance term .
But how can we derive the estimates for
We firstly rely on the SLR.4 assumption to derive two equations:
where the second equation comes from the covariance formula and the fact that .
These are called population moment restrictions
Using then the sample moments from the population, we can get estimates of the population moments.
Recall:
We rewrite as:
Plugging this into and solving yields the familiar slope estimator:
To obtain the intercept , start from the sample first-order condition (1):
Rearrange:
Divide by and use the sample means and :
Substituting the closed-form gives the explicit intercept estimate:
This algebra shows the OLS line passes through the point and yields the intercept as the sample mean of minus the slope times the sample mean of .
Intuition: the slope estimate is the sample covariance between and , divided by the sample variance of .
- if are positively correlated, the slope will be positive.
- if are negatively correlated, the slope will be negative.
Moreover, intuitively, the OLS is fitting a line through the sample points such that the sum of squared residuals is as small as possible.
Algebraic Properties of OLS:
- the sum of the OLS residuals is zero.
- the sample average of the OLS residuals is zero.
- the sample covariance between the regressors and the OLS residuals is zero.
- the OLS regression line always goes through the mean of the sample.
Moreover, we notice that each observation is made up of an explained and unexplained part ().
Using this terminology, we can define:
To understand how well does the sample fit the regression line, we define:
The second equality follows from the decomposition of total variation. Write each deviation from the mean as the explained part plus the residual: . Then
The cross term vanishes because OLS residuals are orthogonal to the fitted values (equivalently to the regressors):
Therefore
Dividing by gives
Be aware that, the term linear in a OLS model does not mean a linear relationship between the variables, but a model in which the parameters enter the model in a linear way.
The following are all linear models (in the parameters):
Implication of the Simple Linear Regression
- OLS is unbiased (the proof depends on the four assumptions; if any fail, OLS is not necessarily unbiased.)
- The sampling distribution of our estimates is centered around the true parameter.
But, following the second implication, how likely is it that the true slope is slightly larger, smaller or zero?
This question can be translated into another assumption:
- SLR.5 Homoskedasticity: assume
Using then the Homoskedasticity assumption, we can derive the variance of .
Hence, is also the unconditional variance, called the error variance.
We can then use this formula to find the variance of :
- the larger the error variance , the larger the variance of the slope estimate.
- the larger the variability in the (), the smaller the variance of the slope estimate.
Finally, starting from the residuals , we can form an unbiased estimate of the error variance (often called the mean squared error (MSE)), denoted by :
Intuition: is the truth; is our best guess based on the sample we have.
Moreover, we divide by because, estimating , we lost 2 degrees of freedom.
3 Multiple Regression Analysis: Basics
The key problem with simple linear regression is that the assumption is often problematic.
Consider, for example, that the true population model is:
The previous assumption states that the error term has (zero) expected value (no trend) or, in other words, does not correlate with the .
This causes to be biased compared to the "true parameter", so it doesn't measure the causal effect of education on wage.
Thus, instead of assuming that multiple variables are uncorrelated with the output variable, the multiple regression model allows to include them directly in the model.
- is still the intercept
- are the slope parameters
- is the error term.
We still need a zero conditional mean: , that means, in other words, that all the factors that influence the outcome are included in the model.
In order to estimate the parameters, we still use the Ordinary Least Squares method and we minimize the residuals:
leading to conditions to derive parameters.
The estimate model allows a ceteris paribus interpretation, that means that a change in , , leads to a change in given by , keeping all the other fixed.
Frisch-Waugh-Lovell (FWL) Theorem
Given a multiple regression model (two regressors, for example) , the coefficient can be found in two steps:
- Regress on :
Save then the residuals . This represents the part of not correlated with .
- Regress on the residuals:
The resulting coefficient will be identical to of the original model.
The previous definition of is still valid, but we can add the following remarks:
- is the squared correlation coefficient between and the predicted .
- never decreases when adding independent variables to a regression (it usually increases).
- Because it increases when the number of parameters changes, it is NOT a good measure for comparing different models.
As in the simple regression model, we can formalize the assumptions for the multiple one:
-
MLR.1: Linear in parameters
in the population model the following relation holds: -
MLR.2: Random sampling
we have a random sample of size : -
MLR.3: No perfect collinearity (sample variation in explanatory variables) no explanatory variable is an exact linear combination of the others, and each regressor has variation in the sample.
-
MLR.4: Zero Conditional Mean
or, for every slice of population determined by , the average of is zero.
This also implies:
also called the Population Regression Function.
Then, we can derive the following:
Implication 1: Unbiasedness of OLSUnder the previous assumptions, the OLS estimator is unbiased: .
- If we include irrelevant variables in our model, the OLS estimator remains still unbiased.
- If we exclude relevant variables, OLS will usually be biased.
Let's suppose the true model is:
but our model is:
and we actually estimate:
The slope parameter will then be:
Recall that the numerator is:
Since , it implies that:
Note that the term after is the slope from the regression of on :
so we have:
| Corr() > 0, > 0 | Corr() < 0, < 0 | |
|---|---|---|
| Positive bias | Negative bias | |
| Negative bias | Positive bias |
Then we can consider two corner cases:
- : doesn't affect :
- , so uncorrelated in the sample.
Assumption 2: Efficiency of OLS Estimator
Once we know that the estimate is centered around the true parameter, we want to understand how it is distributed.
If we add a fifth assumption (MLR.5 Homoskedasticity), we know that:
we also know/derive that:
Theorem: Sampling Variances of the OLS Slope Estimators
Given the assumptions from MLR.1 to MLR.5,
where
- is the total sum of squares of the predictor to its mean ( indexes observations, indexes the variable)
- is the from the auxiliary regression of on the other regressors (including the intercept).
Intuition and consequences:
- a larger increases the variance of the estimator.
- a smaller (less spread in ) increases the variance of the estimator.
- a larger (strong linear dependence between and the other regressors) increases the variance of the estimator this is the multicollinearity effect.
Notes:
- If you only have one regressor, drop the subscript: and , recovering .
- The Variance Inflation Factor is it quantifies the multiplicative inflation of the variance due to collinearity.
Let's analyze now what happens if we mis-specify the model. Consider again the true and the mis-specified models:
In this case the estimated variance equals .
On the other hand, the variance using the true model equals:
So, unless are uncorrelated:
Intuition:
- the variance of the estimator is smaller in the mis-specified model.
- the mis-specified model is biased.
- As the sample size grows, the variance of each estimator shrinks to zero, making the variance difference less important.
Estimating the error
- Estimate of the error variance
where represents the degrees of freedom.
- Standard deviation of :
- Standard error of :
Theorem: Unbiased Estimation of ::
Under the assumptions MLR.1 to MLR.5, the estimator is unbiased, .
Theorem: Gauss-Markov Theorem
Under the assumptions MLR.1 to MLR.5, the OLS estimators are the best linear unbiased estimators (BLUEs) of :
- Best: estimators have the lowest possible variance
- Linear: estimators are a linear function of
- Unbiased: expected value equals the population parameters.
4 Multiple Regression Analysis: Inference
So far, we've seen that, given the MLR 1-5, the OLS is BLUE (most precise, most accurate).
To do hypothesis testing, we add another assumption.
MLR. 6: Normality (Classical Linear Model [CLM] Assumption): the disturbance is independent of and it is normally distributed with zero mean and variance : .
Under this assumption, conditional on the sample values of the independent variables we obtain:
(the coefficient estimate is normally distributed around the true beta)
This implies that:
(the standardized average deviation from the true value is standardized normal)
Furthermore, if we use the estimate of the variance of the disturbance (), under the CLM assumptions we obtain:
where and is the degree of freedom.
This result will be useful to determine how likely an estimate is similar to .
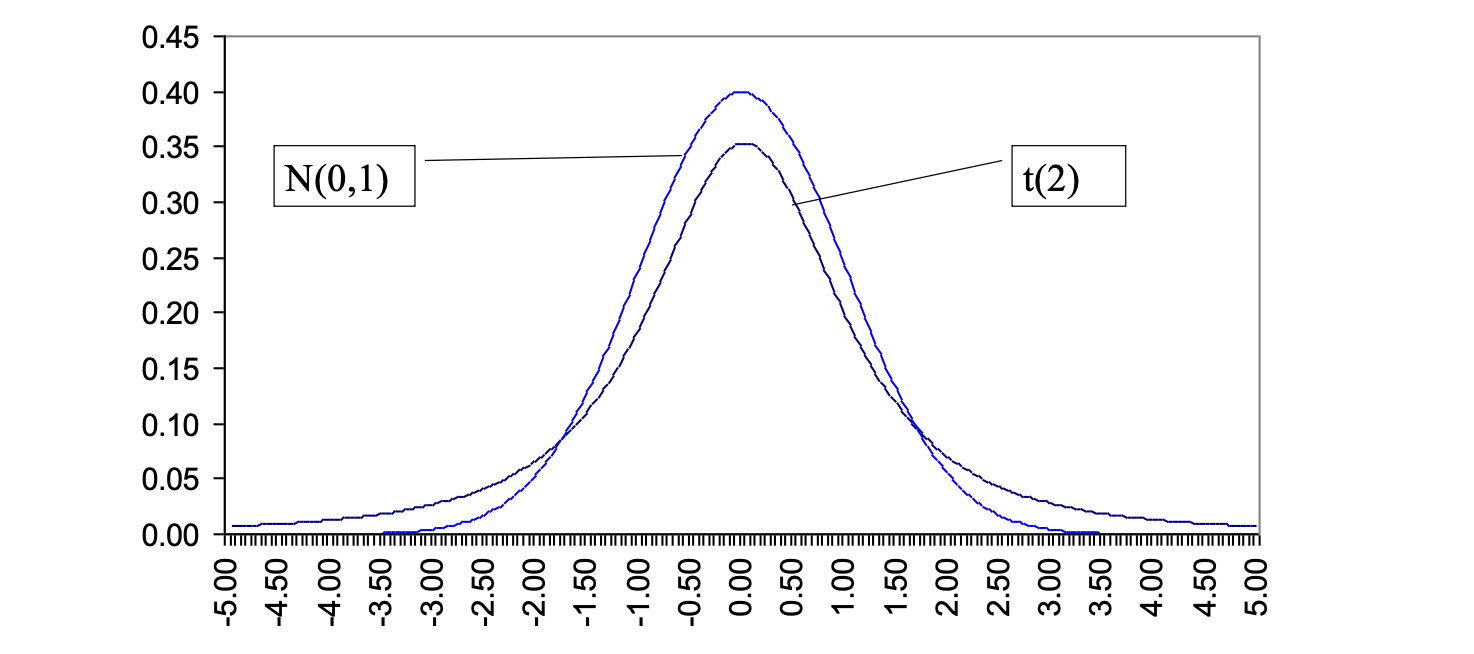
Both the -Student and the Normal distribution are symmetric bell-shaped but the -Student:
- has fatter tails than the normal
- converges to the normal for an infinite sample
- is conditional to the degree of freedom
- can be approximated with a normal distribution where the degree of freedom or similar.
Test Hypotheses
Before starting with the test, let's take a look to the different errors:
- Type I Error: we reject the null hypothesis when it is true (false positive).
- Type II Error: we don't reject the null hypothesis when it is false (false negative).
Test
- Set up the hypothesis. can be one-sided () or two sided ().
- Determine the -statistic using the estimates for .
For example, as seen before:
-
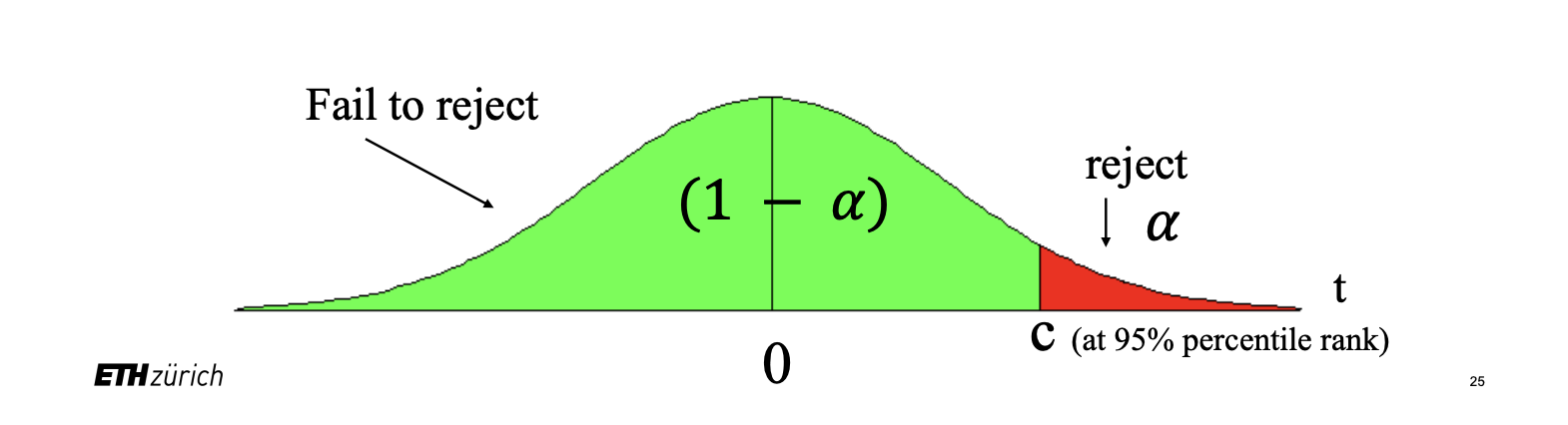
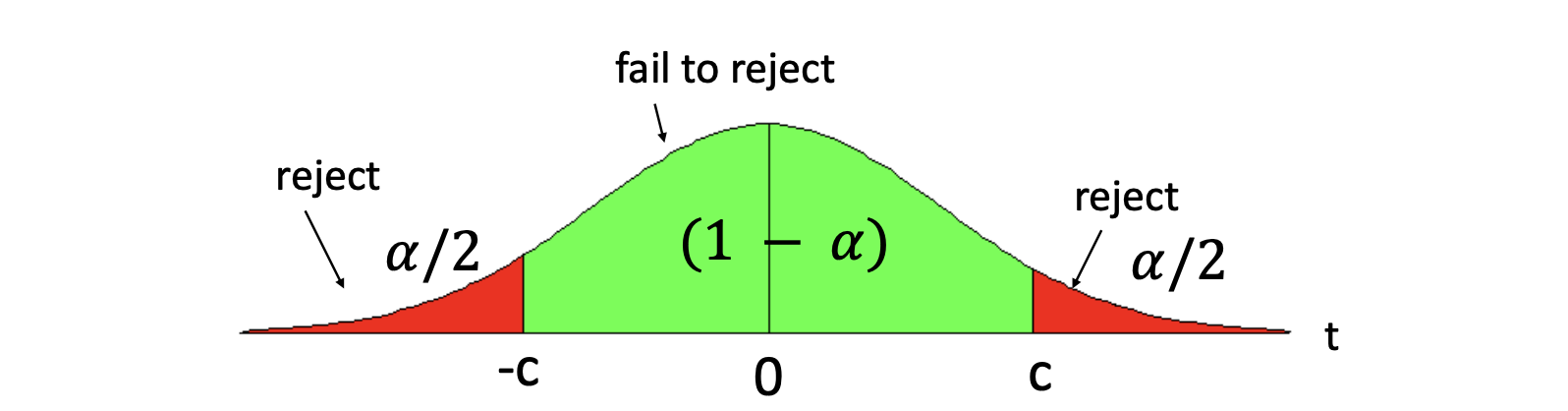
Select a significance level, or, in other terms, the chance to make a Type I error and determine the critical value, depending if it is a one- or two-sided hypothesis.
-
Decide: reject if the absolute value of the -statistic is larger than the critical value.
For example, let's consider the following model:
-
We set up the hypothesis: (: education doesn't increase employment)
-
We calculate
-
We consider using (confidence level) and degree of freedom
- is the ( quantile of the distribution of the test for a two-sided test
- is the quantile for an upper-tail test
- is the quantile for a lower-tail test
-
We reject if (if use )
- If we reject the null hypothesis, we typically say: _ is statistically significant / has a statistically significant effect on at the (significante) level
- Note that is the confidence level!.
Graphically:
- A coefficient is significant at the % level when its estimate is large relative to its standard error when its absolute -statistic is large enough.
- Do not confuse the size of an estimate with significance: a large effect can be imprecise, and a small effect can still be precisely estimated.
- Significance answers a hypothesis-testing question (it does not tell you whether the effect is economically important)
- When a question asks for the number of significant coefficients, count the coefficients that reject the null individually, not the joint significance of the whole regression.
- The intercept is tested exactly like any other coefficient include it unless the question explicitly excludes it.
- If a coefficient is not significant data do not provide enough evidence against the null at the chosen level.
More generally, we can test whether an estimate fits a specific value: .
In this case, we use the appropriate -statistic: , where for the standard test.
Confidence Intervals
Another way to use statistical testing is to construct confidence intervals using the same critical value for a two-sided test.
A confidence interval is defined as where is the percentile in a distribution.
P-Values for -TestsAn alternative approach is to calculate what is the smallest significance level at which the null hypothesis would be rejected given the data.
So we compute the -statistic and we look up at which percentile it is in the appropriate -distribution. This is called the p-value.
The p-value represents the probability that we would observe the -statistic we did, if the null were true.
Testing more complex hypotheses - Linear CombinationSuppose we want to test if is equal to another parameter, that is: . Then the statistic test is .
But, if we expand the formula:
So we need , which we don't usually have.
To avoid this, we can use the following "trick".
We set . To do that, we also have to substitute in our model.
So, for example, we can consider:
Multiple Linear RestrictionsSo far we tested a single linear restriction (). Now we want to jointly test multiple hypotheses about the parameters.
A typical example is testing "exclusion restrictions", that means knowing if a group of parameters are equal to zero.
Then the null hypothesis might be something like: , but we cannot check each statistic separately because we want to know if the parameters are jointly significant.
We instead need to estimate:
- the restricted model without all the
- the unrestricted model with all the included.
Intuition: we want to know if the change in SSR is big enough.
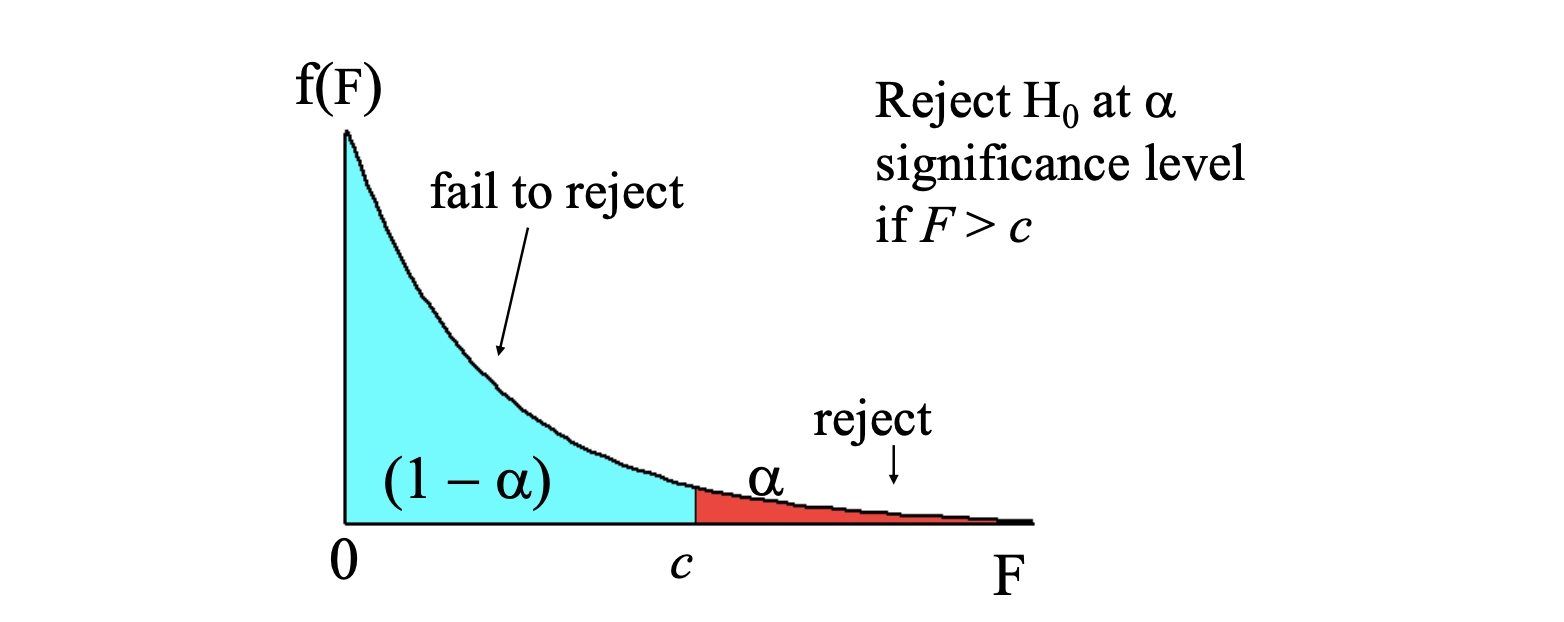
This is called the -statistic, defined as:
where is the restricted, the unrestricted. Note that the statistic is always positive.
Intuition: the statistic is measuring the relative increase in the SSR when moving from the unrestricted to the restricted model.
.
To decide if the increases in SSR is "big enough", to reject the exclusions, we compare if with the distribution, indeed we know that: where:
- is the numerator degrees of freedom
- is the denominator degrees od freedom.
OLS asymptotics
Under the Gauss-Markov assumptions the OLS is BLUE; however they are not always fulfilled with real data. Large samples (big data!) come to our rescue! It can be shown that some nice properties remain intact if . (Larger samples allow us to relax some assumptions).
- Consistency: if estimators are consistent, that means that the distribution of the estimator collapses to the parameter value.
This implies that when we can use MLR.4 (zero mean and zero correlation).
Just as we derived the omitted variable bias earlier, we can think about the inconsistency (asymptotic bias).
Consider the true model and the estimated model: , so that .
In this case, , where , which tells us how much our estimate () deviates from the true parameter ().
Intuition: inconsistecy is a large sample problem: it does not go away as we add data.
Large Sample Inference
So far, we relied on assumption about normal distribution of errors, but this assumption can often break down! Again, large samples come to the rescue: as , the central limit theorem shows that OLS estimates are asymptotically normal.
Thus, we no longer need to assume normality with a large sample, we get it anyway.
If is not normally distributed, we sometimes will refer to the standard error as the asymptotic standard error. In general, we can expect standard errors to shrink at a rate proportional to the inverse of .
Asymptotic EfficiencyThere are other estimators besides OLS that are consistent. However, under the Gauss-Markov assumptions, the OLS estimators will have the smallest asymptotic variances; therefore we say that OLS is asymptotically efficient.
5 Multiple Regression Analysis: Further Issues
To test hypotheses about estimates, we previously relied on assumption about normal distribution of errors (MLR.6) in order to redive and distributions.
This implied that the distribution of given was normal as well.
However, this assumption about normality can often break down! (example: a clearly skewed variable, like wages, arrests, savings etc., cannot be normal, since normal distributions are symmetric).
Also in this case, large samples are the solution: if the Central Limit Theorem shows that OLS estimates are asymptotically normal.
In other terms, for any population with mean and standard deviation , the sampling distribution of the sample mean is approx normal with mean and standard deviation .
Secondly, the -distributoin approaches a normal distribution for a large (degree of freedom), so we no longer need to assume normality with a large sample.
As we said, if the error is NOT normally distributed, we sometimes will refer to it as the asymptotic standard error. (We can expect standard errors to shrink at rate proportional to the inverse of ).
Further Issues in Multiple Regression Analysis: Scaling Variables
Changing the scale of the variable will lead to a change in the scale of the coefficients and the standard error, without a meaningful change in significance/interpretation. The same applies for a change in .
Occasionally, we will see references to standardized coefficient, calculated using the standardized version of , so coefficients reflect a standard deviation change of .
Functional FormOLS can also be used for relationship that are not strictly linear in by using non-linear functions of (as long the model is linear in the parameters).
| Model | Equation | Interpretation |
|---|---|---|
| Level-level | ||
| Level-log | ||
| Log-level | ||
| Log-log |
Log Models
- they are invariant to the scale of the variables since it's all about percentage changes.
- they give a direct estimate of the elasticity
- for models with , the conditional distribution is often heteroskedastic or skewed, while is often less so.
- the distribution of is narrower, limiting the effect of outliers.
Note that, when using the log form, variables have to be positive!
Quadratic ModelsFor a model like we know that:
- if is positive and is negative, is increasing in at first and then decreasing.
- if is negative and is positive the opposite happens.
- The turning point is calculated setting the derivative to zero and lies at:
AdjustedR-Squared
Recall that always increases as more variables are added to the model since never decreases with more variables:
The adjusted takes then into account the number of variables in the model:
The adjusted penalizes models with more variables, especially for low and high , and increases only when additional variables are added whose -statistic is larger than . This means adding variables with poor explanatory power decreases adjusted .
In other terms, we usually use adjusted to compare models with the same , but never with models with different .
(Standard Errors for) PredictionsSuppose we want to use our estimates to obtain a specific prediction at a point . The conditional mean is
To assess the precision of this predicted mean, compute the standard error
which can be obtained from the covariance matrix of the OLS estimates. The standard error for a new observation also adds the error variance .
Regression with Dummy Variables
A dummy (binary) variable is a variable that takes the value 1 or 0.
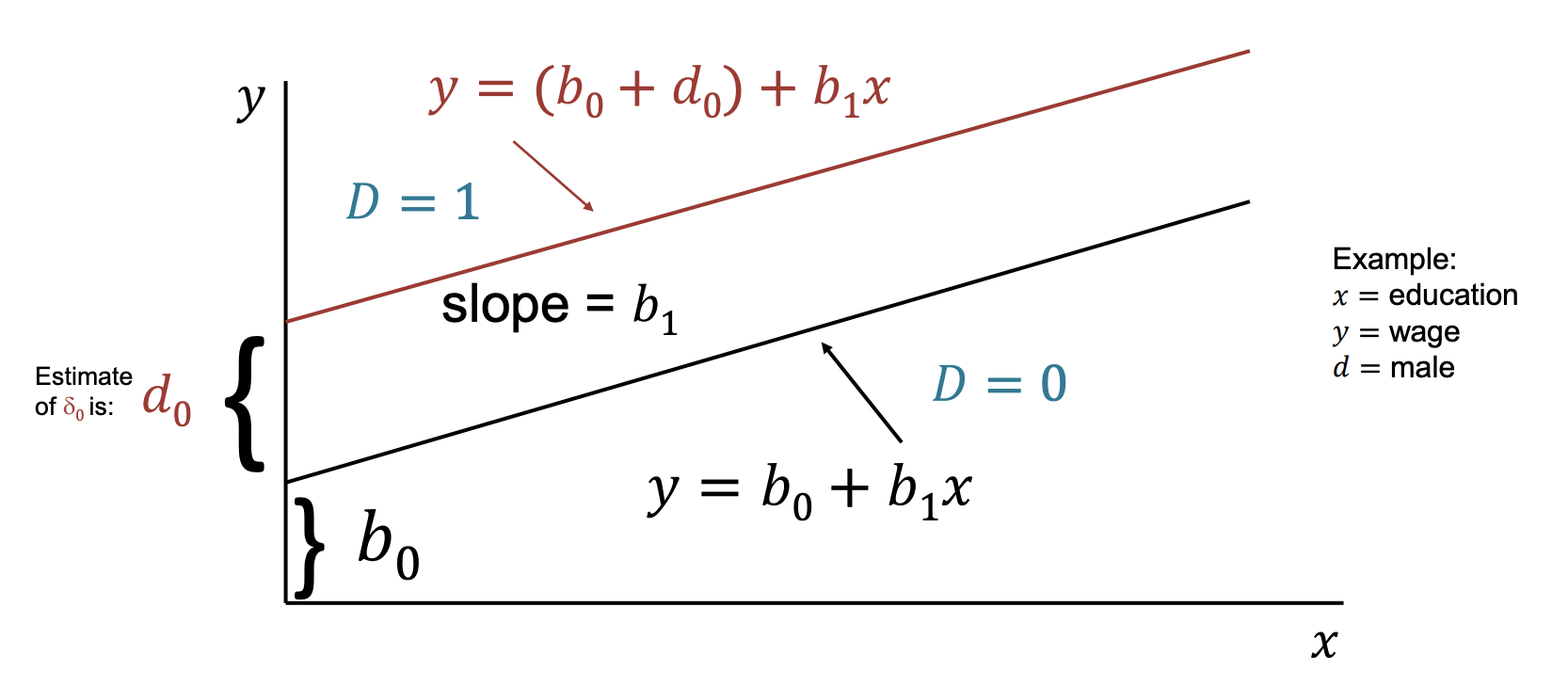
Consider a simple model with one continuous variable and a dummy :
- if female, otherwise.
- : education in years.
- : wage.
This can be interpreted as an intercept shift:
- if then (male, base group).
- if then (female).
Dummies for Multiple Categories
Any categorial variable can be turned into a set of dummy variables. Because the base group is represented by the intercept, if there are categories there should be dummy variables.
Note that we can model interaction between dummies to divide in subgroups and between dummies with continuous variables to model a change in slope.
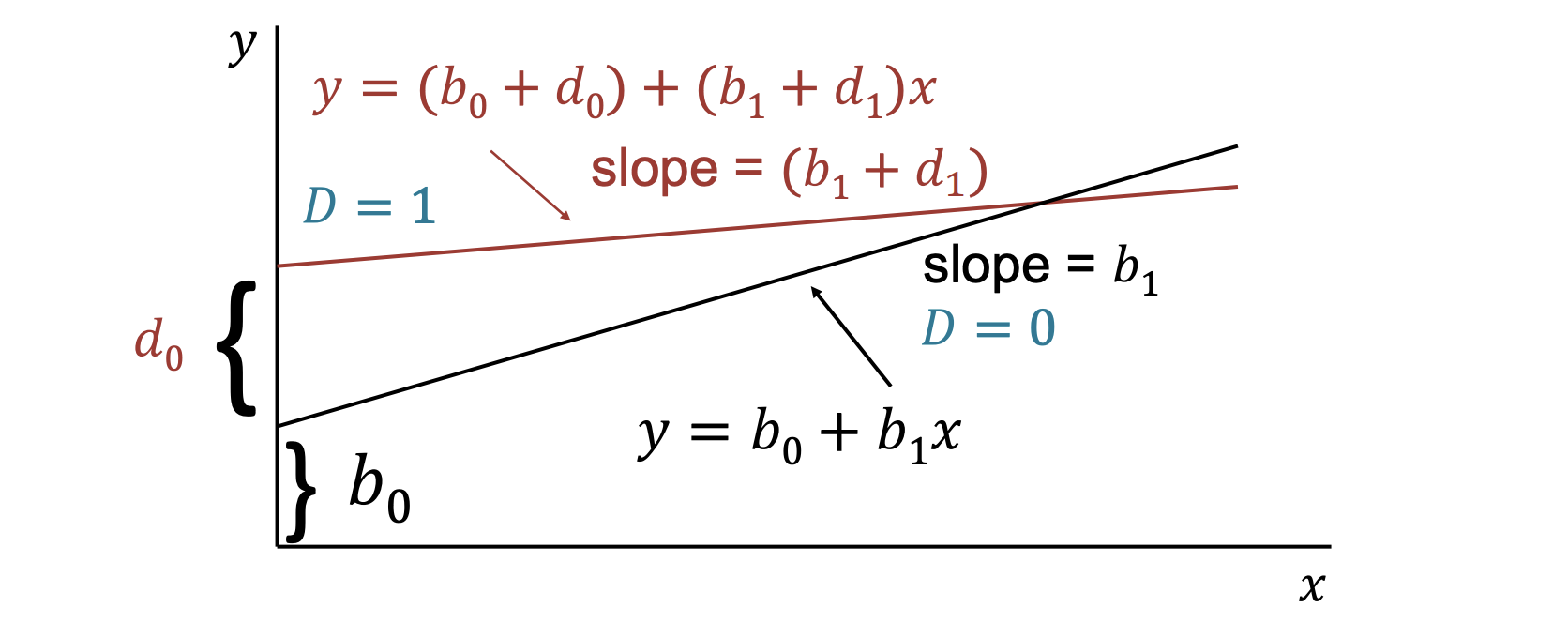
Testing whether a regression function is different for one group versus another can be thought of as testing for the joint significance of the dummy and its interactions with all other variables.
So we can estimate the model with and without the interactions and form a -statistic (very tedious in practise!).
The Chow TestWe can compute the -statistic without running the unrestricted model with all interactions with continuous variables, but intead we can:
- run the restricted model for group 1 (using observations ) and get
- run the restricted model for group 2 (using observations ) and get
- run the restricted model for all (using ) and get
- compute the -statistic as:
knowing that .
We then set as "all coefficientsd are equal agross groups", that rewrites as:
then we compute as defined above and we set as the upper quantile of .
If , we reject at the significance level (note that is an upper-tail test since it's non-negative).
Dummy as Dependent Value: Linear Probability Modelwhen is binary model, so we can write our model as:
- represents the change in the probability when changes by 1 around the mean.
- the predicted is the probability
However, potential problems arise since the prediction can be outside .
Also, this model will violate the assumption of homoskedasticity, which will affect inferece.
Despite everything, OLS is usually a good starting point when is binary.
6 Heteroskedasticity and Other Problems
Assumptions Multiple Linear Regressin (MLR) Model-
MLR.1: Linear in parameters
- In the population model, the following relationship holds:
-
MLR.2: Random sampling
- We have a random sample of size :
-
MLR.3: No perfect collinearity
- None of the independent variables is constant, and there are no exact linear relationships among regressors.
-
MLR.4: Zero conditional mean
- The error has zero conditional mean:
-
This implies .
-
MLR.5: Homoskedasticity
- Assume constant conditional variance of the error:
-
MLR.6: Normality
- The disturbance is independent of and normally distributed with zero mean and variance :
Recall that the assumption of homoskedasticity implied that, conditional on the explanatory variables, the variance of the unobserved error was constant.
If this is not true, then the variance is different for different values of and errors are said to be heteroskedastic.
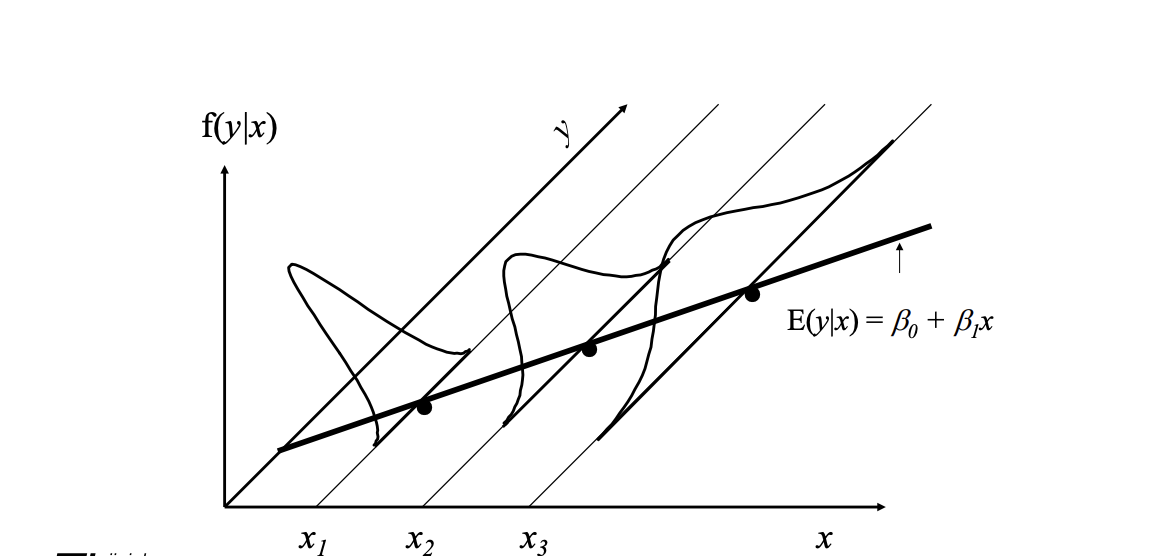
OLS is still unbiased and consistent, even if we do not assume homoskedasticity.
However, the standard errors of the estimates are biased if we have heteroskedasticity.
- If the standard errors are biased, we cannot do inferece based on the usual , , -statistic. (The -statisitc is , and is obtained regressing on all variables. The LM statistic has a -distributio.)
Variance with Heteroskedasticity
For the simple bivariate case, heteroskedasticity implies that:
OLS slope decomposition:
Conditional variance of under heteroskedasticity:
Note that this differs from the homoskedastic case
A valid (consistent) estimator of the variance of when is:
where are the OLS residuals.
Note that this is different from the homoskedastic estimator:
Robust Standard Errors
Consider the model:
With heteroskedasticity, a valid (consistent) estimator of is:
where:
- is the -th residual from regressing on all other independent variables.
- is the sum of squared residuals from this auxiliary regression.
- are the OLS residuals from the original model.
So, the corresponding robust standard error is:
Sometimes a finite-sample correction is used:
As , this correction becomes negligible.
Note that robust standard errors are justified asymptotically. In small samples, -statistics based on robust SE may not be close to a distribution.
Testing for Heteroskedasticity
We want to test:
This statement is equivalent to
only under the additional (usual) assumption that
since
In practice we typically assume , so testing whether is constant across is a valid way to test homoskedasticity.
If we assume the relationship betwee and to be linear, we can test it as a linea restriction:
The Breush-Pagan Test
In this test, we do not observe the error, but we can estimate it with the residuals from the OLS regrssion.
After regressing the residuals squared on all , we can use the to form a or -test.
- The -statistic is distributed as and it is equal to:
- THe -statistic follows a -distribution and is:
Note that the Bresuch-Pagan test detect any linear forms of heteroskedasticity.
The White Test
The White Test allows for general (including non-linear) forms of heteroskedasticity by using squares and cross‑products of the regressors (or by using functions of the fitted values).
We can proceed in two ways:
- Regress the squared residuals on powers and cross‑products of the original regressors (full White specification):
- Regress the squared residuals on the fitted values and its square (simpler form):
Test statistics:
- -(asymptotic) form:
where is the number of explanatory variables in that auxiliary regression (excluding the intercept).
- -form
Notes:
- including all squares and cross‑products allows to detect many nonlinear heteroskedastic patterns
- The LM form is preferred in large samples
Weighted Least Squares
While it is always possible to estimate robust standard errors, if we know something about the specific form of heteroskedasticity we can obtain a more efficient estimates.
Intuition: transforming the model into one that has homoskedastic errors if we do it, we call the estimators weighted least squares.
Suppose the original model is:
and heteroskedasticity has the form:
We can define the variable:
Because is a function of , conditional on it is a constant and has constant variance.
Hence the transformed error is homoskedastic.
We now trasform the whole equation model by dividing the original model by by :
We can then define the transformed variables as:
so we obtain:
So OLS on this transformed model is BLUE (under the usual assumptions).
But why this is called “weighted” least squares?
OLS on transformed data minimizes:
Therefore WLS minimizes weighted residual squares with weights
Intuition:
- If is large, observation has high error variance lower weight.
- If is small, observation has low error variance higher weight.
Feasible GLS (FGLS) for Unknown Heteroskedasticity
In reality, we often do NOT know the exact form of heteroskedasticity (), so we need to estimate it.
We generally assume a flexible variance model:
So, under this assumption, we have:
Note that exponential form guarantees , so variance cannot be negative.
From this assumption:
if we assume independent of and
If we take the logarithms we obtain:
Since is unobserved, use OLS residuals from the original regression and estimate:
Let fitted values from this auxiliary regression be , then:
with weights equals .
Specification and Data Issues
We have seen that a linear regression can really fit nonlinear relationship, but how do we know if we have the right functional form for our model?
Firstly, economic theory shoud guide you, but a test of functional form can be useful.
RESET test lies on a trick similar to the special form of the White Test.
Instead of adding functions of the directly, we add and test functions on :
- estimate
- test:
- a significant -test suggests that the model is not correctly specified (using or )
Intuition: the RESET adds nonlinear (and/or interaction) functions of the fitted values to the regression to detect whether important non-linearities or omitted transformations are missing from the specified model form.
Under the null hypothesis the added coefficients (here , ) are zero, so the restricted model (original regression) is OK with respect to them.
How to read the F-statistic:
- Degrees of freedom: numerator number of added terms (2 here); denominator = , where is the number of parameters estimated in the original model (including the intercept). The test compares the restricted SSR to the unrestricted SSR.
- Decision rule: compute the -statistic and either compare it to the critical value from at the chosen or use the p-value.
- If or , reject and conclude there is evidence the model is misspecified.
Proxy Variables
What if a model is mis-specified because no data is available on a important variable?
It's possible to avoid omitted variable bias using a proxy variable. A proxy variable must be related to the unobservable variable.
Consider the true model
and suppose we do not observe the true regressor but we have an observed proxy .
Then we can regress the proxy as:
with . Then
Then we can regress on the proxy by substituting:
into the true model to get
Hence:
- The coefficient on the proxy is ; the intercept shifts by .
- The error in the regression using the proxy is .
- For OLS on to give consistent estimates of we therefore need (so the proxy error is uncorrelated with ) and the usual condition.
If instead the observed proxy is a linear combination of other regressors (a bad proxy), for example
then substituting directly gives
so the coefficients on are generally biased (they absorb the proxy's dependence on ).
Intuition: condition for a valid proxy the proxy must contain variation that is informative about (large ) and its measurement error must be uncorrelated with regressors and the structural error.
Measurement Error in a dependent variable
Consider the following situation. We would like to esitimate: but we only measure the true value plus an error:
We then define the measurement error .
Therefore, we really estimate:
- if and are uncorrelated, then the estimate is unbiased
- if , then the estimate of is biased
Measurement Error in an Explanatory Variable
We want to estimate: , so we define the measurement error as and we assume:
Therefore, we really estimate:
The effect of the measurement error depends on assumptions abou the correlation betweeen :
- if : OLS remains unbiased but we get higher variaces (similar to the proxy variable case)
- if (case known as the Classical errors-in-variavles assumption) are correlated with:
This implies that is correlated with the error so the estimate is biased:
Note that the multiplicative error is so the estimate is biased toward zero (attenuatoin bias).
Nonrandom Samples
If the sample is chosen on the basis of an variable, then estimates are unbiased.
If the sample is chosen on the basis of the variable, then we sample selection bias.
Note that sample selection can be very subtle! For example, looking at wages for workers (people choose to work for this wage) is different that looking for the wage offers.
OutliersSometimes an individual observation can be very different from the others and can have large effects on the outcome. Outliers are often caused by errors in data entry (reason why looking at data summary statistic is very important!).
Multiple strategies to deal with outliers:
- fix observation where it is clea there was just an extra zero or similar
- drop outlier observations and show regressions with/without them
- winsorize estreme observations (for istance: observations below set to and above set to ).
More on winsorization (Wikipedia)
7 Time Series Data
Time series data have a temporal ordering:
Recall that, on the other hand, cross sectional data : .
So, instead of having a random sample of individuals, we have one realization of a stochastic process, therefore we need to adapt some assumptions for OLS.
Examples of Time Series Models- A static model related contemporaneous variables:
- A finite distributed lag (FDL) model with otder (in which we then have lags) allows one or more variables to affect with a lag:
We call the impact propensity that reflects the immediate change in given by .
represent the change in periods after a one-period change in . (so for a temporary 1 period change in , returns to its original level in periods).
We call the long-run propensity (LRP) that reflects the long-run change in after a permanent change in .
Properties
We now take some time to understand which properties need to be adapted to time series data in order to use OLS in a proper way. Recall that the MLR assumptions are (as discussed before):
-
MLR.1: Linear in parameters:
- MLR.2: Random sampling
- MLR.3: No perfect collinearity
-
MLR.4: Zero conditional mean:
-
MLR.5: Homoskedasticity:
- MLR.6: Normality
Recall also that:
- MLR.1 to MLR.5 OLS is unbiased and BLUE
- MLR.5 we can do inference (hypotesis testing) in small samples.
In order to still have a unbiased OLS, for time series data we need the following properties:
-
TS.1: Linear in parameters
- The stochastic process follows the linear model:
-
TS.2: No perfect collinearity
- In the sample, no independent variable is constant and no independent variable is a perfect linear combination of the others.
-
TS.3: Zero conditional mean
- where and collects all explanatory variables for all time periods.
- Implication: the error term in any given period is uncorrelated with explanatory variables in all periods (regressors are strictly exogenous).
-
Alternative assumption (weaker)
- This implies regressors are contemporaneously exogenous.
- Contemporaneous exogeneity is generally sufficient for consistency in large samples.
Note that we skipped the assumption of a random sample:
- the key impact of the random samples is that is independent since the exogeinity assumption takes are of it in this case.
- Based on these 3 assumptions, the OLS estimators are unbiased.
- TS.3 can easily break down. If we consider for example when past value of affect but we just set up a contemporaneous model.
Variances of OLS estimators for Time Series Data
To derive variances of estimators, we start with some assumptions. We then assume that the variance is independent of all the 's and it is constant over time (TS.4):
We also assume no-serial correlation (TS.5):
Under TS.1 to TS.5 (Gauss-Markov Assumptions) the OLS variances in the time-series case are the same as in the cross-section case, consequently we have:
- the estimator of is the same
- OLS is BLUE.
With the additional inference (TS.6) of Normality (errors are independent of and are independently and identically distributed as Normal ):
- inference is the same as before.
Comparison of the assumptions
| Cross-section data | Time-series data |
|---|---|
| MLR.1: Linear in parameters; | TS.1: Linear in parameters; |
| MLR.2: Random sampling | No direct counterpart (time series are ordered in time, not randomly sampled) |
| MLR.3: No perfect collinearity | TS.2: No perfect collinearity |
| MLR.4: Zero conditional mean; | TS.3: Zero conditional mean; |
| MLR.5: Homoskedasticity; | TS.4: Homoskedasticity; |
| No serial-correlation assumption in cross-sectional baseline | TS.5: No serial correlation; |
| MLR.6: Normality | TS.6: Normality |
Trending
Some examples of trend:
- linear trend:
- exponential trend:
- quadratic trend:
Regression with a linear trend is the same thing as using a "detrended" series in a regression.
Detrending implies regressing each variable on (including a constant) and then take the residuals of this regression (the result is the detrended series).
Some advantages of detrending for calculating :
- time-series regression tend to have a very high as the trend is "very well explained".
- from a regression on detrended data better reflect how well explain .
Seasonality
Often time-series data has some periodicity, in this case there are two major practices:
- adding a set of seasonal dummy variables
- series can be ajusted before running the regression.
8 Panel Data
- Pooled cross sectional data refer to data on individuals and periods where individuals cannot be followed explicitily over time (independent sampled observatoins with knowledge about the time dimension)
- Panel data follow the same cross-sectional units over time.
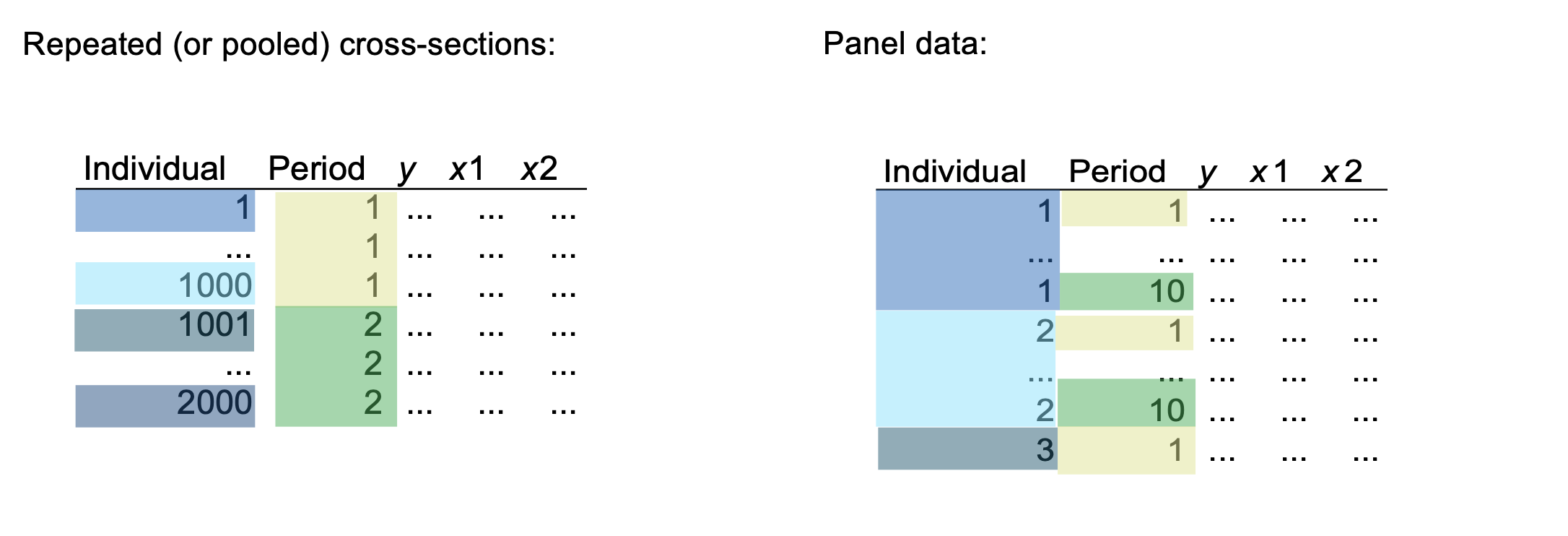
Why should we use pooled cross-sections?
- to get a bigger sample size and then more degrees of freedom for a more precise estimate
- to investigate if the relations evolve over time
- Chow test: test if parameters change over time
- to have more dimensions of variation: cross-section and time (difference in difference estimation, especially useful for evaluating policies)
- Example: do house prices at different locations change differently after a climate policy?
The Chow Test
It tests if there is a difference in the coefficients across 2 groups.
Basic idea: it's very similar to having 2 time periods as "groups" using a dummy variable for one of the two periods and test for joint significance of period (1) dummy and the period (2) interaction terms.
If we have two periods/groups, we can do the following:
- compute a proper statistic by running the restricted pooled model using all observations obtain .
- run separate unrestricted regressions for period/group 1 and get , then for period/group 2 and get .
- they form the unrestricted .
- then compute in the case of two periods as:
The Chow test is just a simple test for exclusion/restriction.
- note that we have restrictions
- note that the unrestricted model would estimate 2 different intercepts and slope coefficients, so the denominator degrees of freedom are .
In real-world economics, we can't run randomized experiments (RCTs) for ethical/practical reasons. We can just observe people's choices, which creates endogeneity (people self-select into treatments).
However, having repeated cross sections allows observing random samples of groups across time in data. Often policies can affect different groups differently, leaving a "trace" of variation that is sometimes "as good as randomly assigned" across groups.
We call such events natural experiments because they create an experimental setup with:
- treatment group: the one assigned to treatment and treated after the event happened (but not before)
- control group: the one that does not get treated and has not been treated before.
(Note that the timing and the assignment are outside of anyone's control)
Example: Minimum Wage & Employment (Card and Krueger, 1994)
This analysis focused on the New Jersey raising its minimum wage from 5.05 per hour on April 1, 1992. Pennsylvania did not.
- treatment group: fast-food workers in NJ (subjected to the wage increase)
- control group: fast-food workers in Pennsylvania (no wage change, very close so similar market conditions)
Then the study analyzed the change in employment in the two states, finding that employment in NJ fast food actually increased slightly, in contrast to the traditional economic theory, suggesting that the minimum wage didn't reduce jobs.
Difference-in-Difference
Assume we have an experiment where units are randomly assigned to a treatment (A) and a control (B) group.
To estimate the treatment effect we compare the changes in outcomes from before and after the treatments and across two groups:
and we label this as the Difference-in-difference (DiD) estimator in the group means.
We can then use a regression framework with dummy variables to do the same:
where:
- : Baseline outcome (control group, before treatment)
- : Pre-existing difference between treatment and control (should be if randomized)
- : Time effect for the control group (secular trend unaffected by treatment)
- : Difference-in-difference estimator (the additional change in the treatment group beyond the secular trend)
(Note that this model can be generalized with different dummies and interaction terms for different years)
Using the regression framework furthermore:
- we can produce confidence intervals and do hypothesis testing
- we can add additional variables to control the differences across the treatment and control group.
However, the DiD estimator could be biased:
- if there are already existing trends prior to a policy. In this case, we should get more than 2 periods and show how groups follow different trends prior to the event.
- if the groups are affected by other policies/events at the same time, in this case we should control for some other factors
- spillover from treatment to control groups, in this case simply take a suitable control group that doesn't deviate
- no selection bias if individuals cannot decide which group they are in
Advantage of using (real) Panel Data
With panel data, unlike pooled cross-sections, we can address the omitted variable bias caused by time-invariant individual-specific factors.
Suppose the population model is:
where is the unobserved effect that is specific to the individual and does not vary over time. This forms a composite error: .
If is correlated with the OLS is biased and inconsistent (since we treated as part of the error term without explicitly controlling for it).
We can adopt three approaches to address these time-invariant unobserved effects:
- First-difference (FD) estimator: take the first-difference of the equation, which removes both and
- Fixed-effect (FE) estimator: subtract the individual averages of all variables (demeaning), which removes both and
- Random-effect (RE) estimator: assume that and are uncorrelated (can use all the data more efficiently, but is biased if this assumption fails)
First-difference Estimator
We perform to obtain:
- to estimate this with OLS, we need that each is uncorrelated with , which only holds if is uncorrelated with each explanatory variable during the entire time sample
- we need to assume strict exogeneity, for all .
- this can be done for more than just two time periods when .
However, note that when there's little variation in standard errors will be large.
Fixed-effect EstimatorWe then consider the individual mean:
and we obtain the new model where :
- this is identical to including a separate intercept (dummy) for each individual
- we still need the strict exogeneity assumption
- in this case we lose (number of individuals) degrees of freedom by de-meaning and we have to make sure that OLS uses degrees of freedom.
If we compare the two previous models, we see that the main difference lies in the "no serial correlation assumption".
- first-difference estimator's advantage is that unit root (non stationary) problems are solved
- fixed effect is more efficient when is serially uncorrelated
Random Effect
Previously we assume that was correlated with the . If it is not the case, OLS would be consistent, but the composite error would be serially correlated.
In this case, we can use the Generalized Least Squares (GLS) approach and transform the model to make errors serially uncorrelated.
We start by doing:
then we subtract:
to obtain the new model:
we end up with a sort of weighted average of OLS and fixed effects.
- if this is just the fixed effect estimator
- if this is just the OLS
also, the bigger the variance on the unobserved effect , the closer is to FE, the smaller the variance, the closer to OLS.
Usually, it is often more appropriate to use the fixed effect since the unobserved fixed effects are often correlated with the .
The testing procedure is the following:
- Hausman Test (to compare fixed effects with random effects model):
- compare estimates of the -vector with and without the additional random effect assumption
- if the additional assumptions are true, then the estimates should be similar.
Correlated Random Effects approach
We can end up in the case of split up between a part related to the time-averages of the explanatory variables and a part uncorrelated with the explanatory variables.
The resulting model is an ordinary random effects model with uncorrelated random effect but with the time averages as additional regressors:
Note that in this case the -vector is identical to the one of the fixed effect estimator.
We can also test the ordinary FE with the Correlated Random Effect approach, testing for the relevance of the -parameters (Mundlak Test)
9 Instrumental Variables
One of the most problematic assumptions of OLS is the zero conditional mean assumption (the explanatory variables are assumed exogenous) if this doesn't hold, the parameter estimates are biased and inconsistent.
So if the error term contains variables (i.e. if the error term is correlated with them) that are correlated with one of the explanatory variables we can:
- pull the variable out of the error term including more relevant regressors
- in case of panel data, assume that the variable is constant over time.
We consider then an example of regression with endogeneity problems: i.e. :
and we know that contains ability, so , so if we use OLS, is biased and inconsistent due to omission of ability.
To solve this endogeneity problem we use an instrumental variable (IV) denoted as that:
- is correlated with the endogenous variable
- is uncorrelated with the error term
- affects the dependent variable only through the endogenous variable (only by changing )
In the previous example:
- affects the number of years of education, so we have
- indirectly affects wages through its effect on education.
Conditions for valid instruments:
- First Stage: ( must be correlated with )
- Independence: (the instrument must be exogenous)
- Exclusion restriction: Z can affect the outcome only by changing
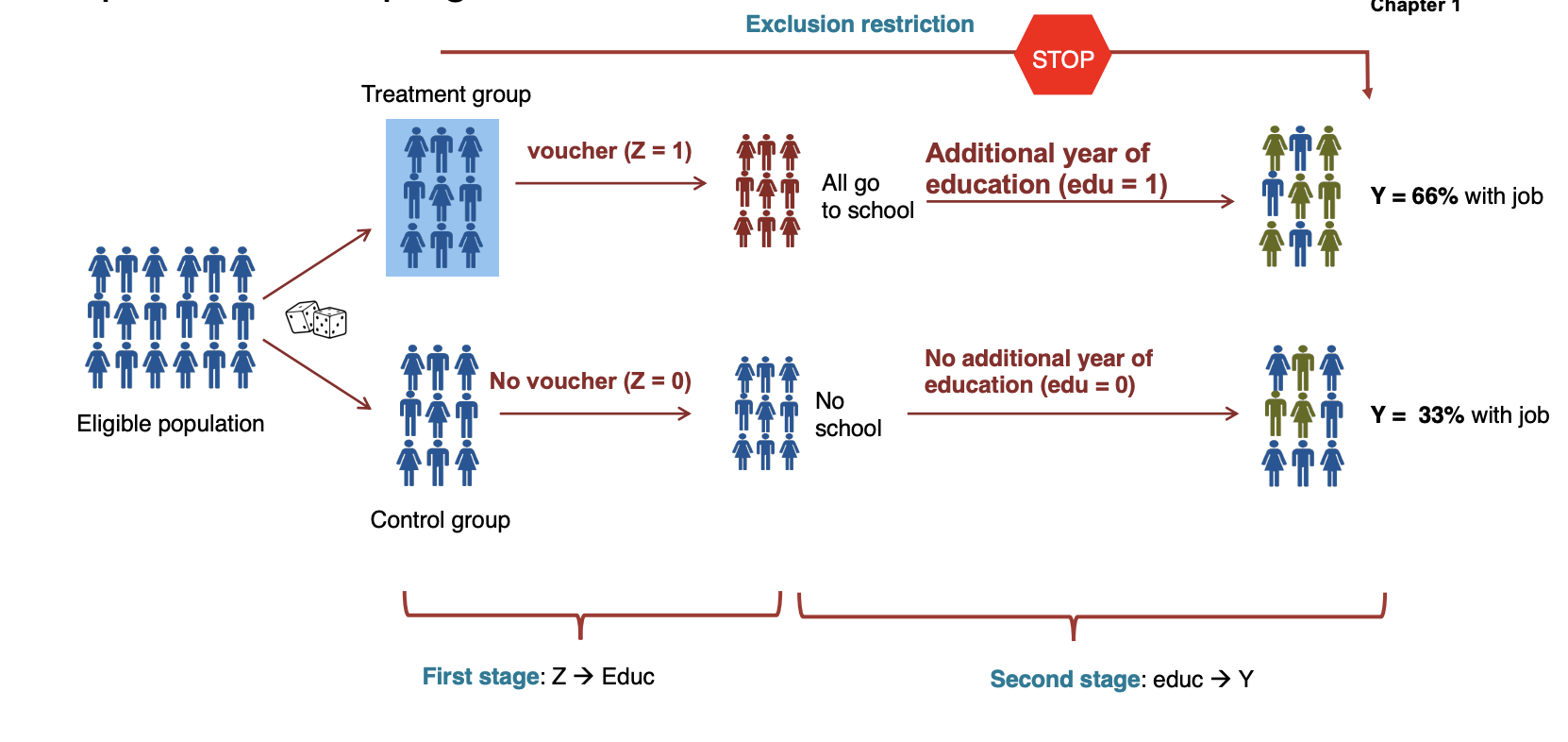
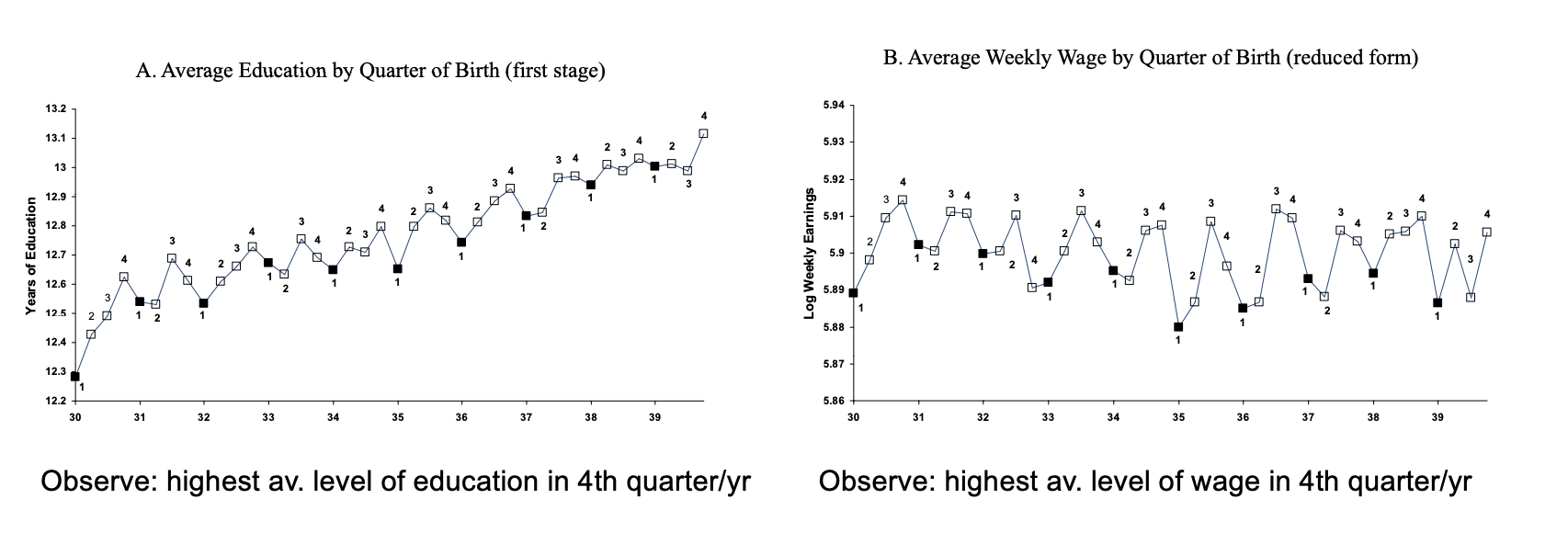
Angrist and Krueger studied which factors out of the full control of individuals (uncorrelated with ) drive education, finding an interesting variation created by US schooling laws in the early 1930:
- Law 1: students enter school in calendar year in which they turn 6
- Law 2: Compulsory schooling requires students to remain in school until they turn , so, since school starts for everyone on the same day of the month, depending on the birth date students can stay in school more or less time.
So these laws can create a natural experiment that influences the number of years of education.
In particular, they observed that, on average, people born in the 4th quarter showed a higher average level of education.
As a consequence, people born in the 4th quarter show higher average level of wage:
Instrumental Variable Estimation in the Simple Regression Case
We consider the model with explanatory variable correlated with the error and instrumental variable (uncorrelated with , correlated with ):
We firstly write the covariance of :
using the linearity of covariance and that , we then get:
Then the IV estimator for is:
Two Stage Least Squares
IV estimation can be extended to the multiple instruments case. In this case we talk about Two Stage Least Squares (2SLS)
We consider the initial structural model (the equation we want to estimate, example):
The goal is to estimate (the causal effect of education on wages) while controlling for .
We are now assuming that both are valid instruments (correlated with and uncorrelated with the error).
Note that is the endogenous variable and are again exogenous regressors.
- Stage 1: the best instrument is a linear combination of all the exogenous variables: so we regress the endogenous variable on the instruments () and .
From this regression we obtain the predicted values, denoted as .
The predicted is then a linear combination of the instruments and the exogenous variable.
Furthermore, the instruments must be jointly significant in explaining and this can be tested using a -statistic (usually we set to ensure strong instruments).
Intuition: the first stage isolates the part of explained by the instruments and the exogenous variable.
- Stage 2: we use the predicted as a regressor:
Note that this regressor uses (exogenous) instead of the "old" (endogenous).
Then the coefficient is the IV estimate of the causal effect of education on wages. Note that in this second stage, the standard errors of the estimates need to be corrected to account for the two-stage procedure. This is typically done automatically in statistical software like STATA.
Intuition: the second stage uses this predicted to estimate the causal effect of education on wages ensuring exogeneity.
Inference with IV estimation
We consider again the case with one endogenous regressor and one instrument .
The homoskedasticity assumption in this case is:
Also, as in the OLS case the asymptotic variance is .
It can be estimated using the sample counterparts:
where:
- are taken from the residuals
- is the sample variance of
- is the R-squared of the regression of on
The standard error is just the square root of this.
So the IV case differs from the OLS only in the from regressing on since in the OLS case we just have .
- since , the IV standard error is always larger stronger the correlation between , smaller the IV error.
- however, IV is consistent, while OLS is not when .
The Effect of poor instruments
If the assumption is false ( are only weakly correlated ) the IV estimator will be unreliable or undefined. This happens because the denominator of the IV estimator depends on the correlation between .
We can indeed compare the asymptotic bias in OLS, IV as:
- IV:
- OLS:
This shows that even small correlation of can lead to large biases particularly if the correlation between is also small.
The Charter School Experiment
The main question is: "do better charter schools produce better pupils?" (But wait, what is a charter school?)
Characteristics of charter schools:
- public schools operating with more autonomy than public schools
- expanded instruction time
- selective teacher hiring
- serve in poor districts
We can answer this question using data from Massachusetts schools in 2005-2008 and regressing:
where (knowledge is power program) is a binary variable indicating where a student attends a KIPP charter school.
The problem is that since more motivated kids might go to charter school.
The solution is a random assignment of schools through lotteries (due to too many applicants and capacity constraints):
- participants were randomly selected to get an offer to attend KIPP however:
- not all applicants with an offer enrolled in KIPP and attended ()
- some applicants without an offer managed to get into ()
We can still exploit the randomization of the offer to extract the causal variation in attendance.
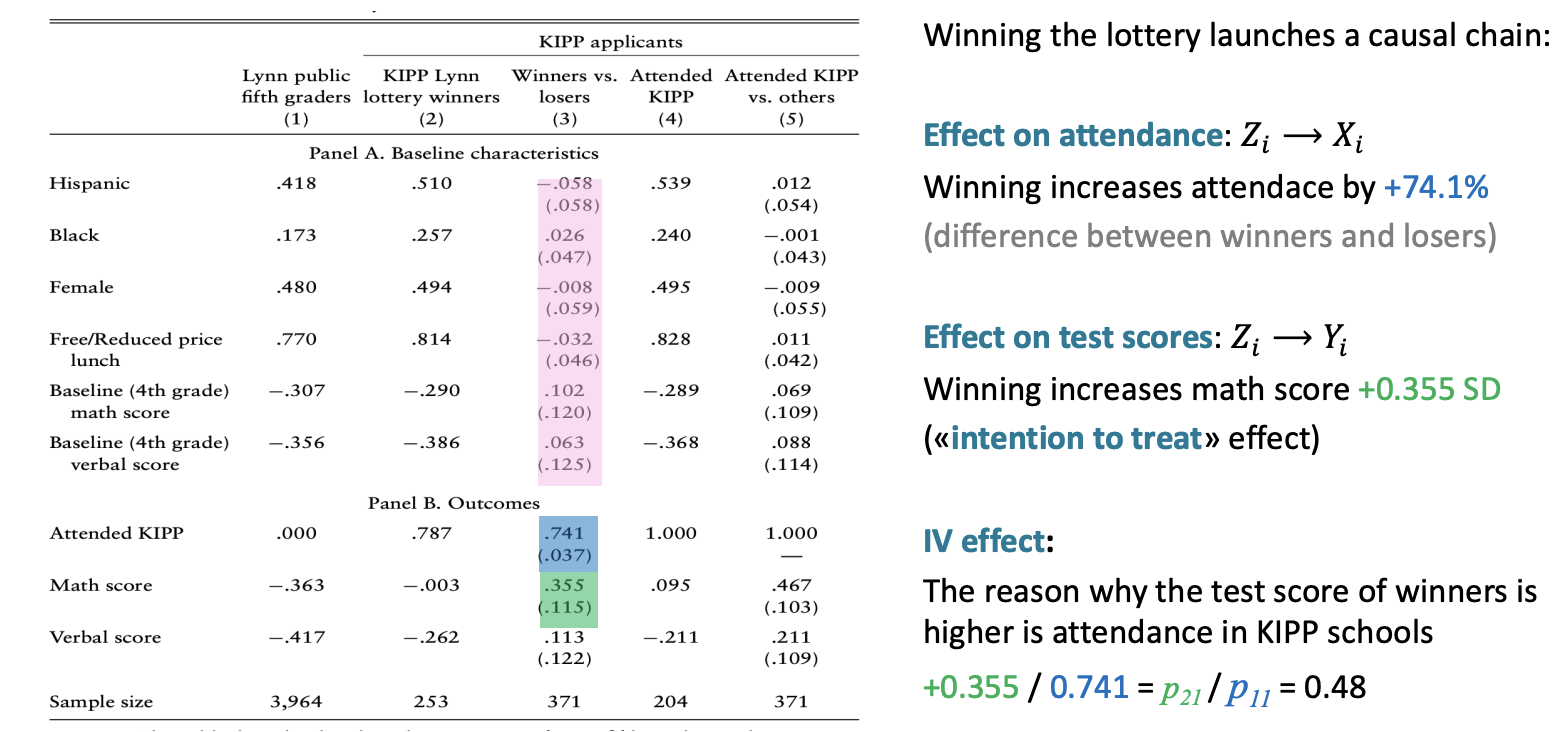
Not all students who win the lottery attend KIPP schools (only 74%). These individuals whose treatment status is determined by the instrument (the lottery) are called "compliers":
- offer KIPP
- offer KIPP
There are individuals that do not care about the lottery outcomes:
- Always takers: attend KIPP whether they win the lottery or not (4.6%)
- Never-takers: never attend KIPP irrespective of the lottery (21.3%)
- Defiers: who attend KIPP only if they lose the lottery (0%).
The IV estimate measures the Local Average Treatment Effect (LATE), which is the average causal effect of the treatment (attending KIPP) for the compliers.
- the IV estimate does not provide information about the treatment effect for the always takers, never takers, defiers this because the IV method relies on the variation in the treatment caused by the instrument (and the treatment status of always takers, never takers and defiers is not influenced by the instrument)
Then the external validity of the IV estimate is limited because:
- the IV estimate is limited to the compliers
- the causal effect for compliers may not be the same of the causal effect for the entire population.
In the case of the KIPP study:
- the IV estimate measures the causal effect of students attending KIPP schools because they won the lottery
- it doesn't measure the effect of attending KIPP for always takers, never taker or defiers
the results are only valid for a subgroup.