These notes are freely taken from the book Machine Learning for Asset Managers (Elements in Quantitative Finance). They are often incomplete and not 100% accurate, as I intentionally skipped mathematical proofs and focused mostly on the practical concepts.
Index
- Introduction
- Denoising and Detoning
- Distance Metrics
- Optimal Clustering
- Financial Labels
- Feature Importance Analysis
- Portfolio Construction
- Testing Set Overfitting
- Bibliography
1. Introduction
Why Not to Do Backtesting
Contrary to popular belief, backtesting is not a research tool.
Backtests can never prove that a strategy is a true positive.
Never develop a strategy just because of backtests.
Strategies must be supported by theory, not only historical simulations.
Your theories must be general enough to explain particular cases, including extreme events (black swans).
Role of Machine Learning (ML)
- ML helps discover hidden variables.
- ML itself does not reveal the relations between variables. Therefore:
- Formulate a theory that binds the elements together.
- Test the theory in different contexts (even where ML found no signal).
Once the theory has been tested, it should stand on its own.
The theory, not the ML algorithm, should make predictions.
Uses of ML
- Existence: ML can indicate the presence of previously unknown relations by predicting outcomes.
- Importance: Feature-importance measures reveal which variables matter more for model performance.
- Causation: ML can support causal inference by comparing predictions.
- Reductionism: Dimensionality reduction can reveal low-dimensional structure and clusters.
- Retrieval: ML scans large datasets to find rare events.
- Outlier Detection: ML identifies anomalies using learned patterns.
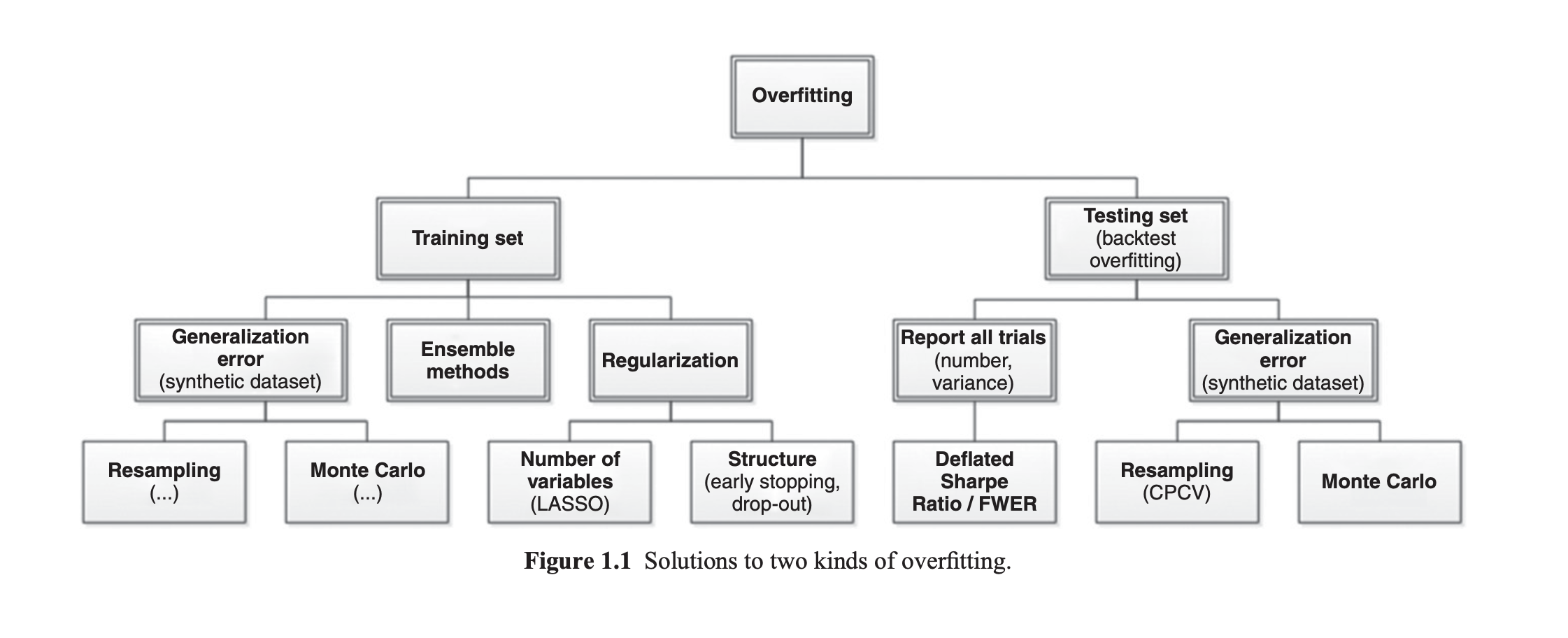
Types of Overfitting
- Train-set overfitting: model fits noise and signal in the training data (learns tiny irrelevant movements).
- Test-set overfitting: repeatedly testing many models on the same test set and selecting the best-performing one.
A useful diagnostic is the generalization gap:
where and are the expected errors (or loss) on training and test sets respectively. A large positive indicates overfitting.
2. Denoising and Detoning
Covariance Matrix
Covariance matrices are empirically obtained, so they contain a
significant amount of noise.
If used directly (e.g., for portfolio optimization),
this noise can make results unstable.
The theorem tells us what the eigenvalues of a covariance (or correlation) matrix should look like if the data is completely random.
- If we compute the covariance matrix of asset returns, some of the eigenvalues may just be noise. (random correlations that don’t carry information).
Consider a matrix with:
- observations (rows)
- assets (columns)
Assume returns have mean and variance . Compute the sample covariance matrix:
Each eigenvalue represents how much variance is explained by a certain “direction” (or factor) in the data.
If the data is purely random, the eigenvalues follow a known distribution: the Marčenko–Pastur distribution.
The theorem tells us that the eigenvalues will lie between two limits:
All eigenvalues between and are
what we expect from random data, they are just noise .
Eigenvalues larger than (or smaller than )
may represent true correlations or factors in the data.
The basic Marčenko–Pastur theorem assumes that all eigenvalues are random.
In real financial data, this assumption is not valid, some eigenvalues capture true, non-random structure, such as market factor (the first principal component, representing systematic market risk), sector effects or other common risk factors.
The Solution: Laloux Adjustment
Laloux proposed an approach to adjust the Marčenko–Pastur model to account for the presence of non-random eigenvalues.
-
Identify non-random eigenvalues, typically the largest eigenvalues (e.g., the first one representing the market mode).
-
Remove their contribution from the variance
- Since these are not random, they should not increase the estimated noise level.
- Adjust the variance:
-
Recompute Marčenko–Pastur bounds
- Use the adjusted variance to compute new limits:
-
Fit the theoretical PDF
- Fit the Marčenko–Pastur distribution wit updated data to estimate how much variance is explained by random noise.
Denoising
When you build a correlation matrix from asset returns, a lot of its eigenvalues come from noise.
If you use this noisy matrix directly (e.g. in portfolio optimization), the results are unstable and misleading.
So, the idea is to denoise the matrix: keep the information from the meaningful eigenvalues (the big ones above the Marčenko–Pastur threshold) and replace the noisy ones with something cleaner.
1. Decomposition of the denoised correlation matrix
Start from the denoised correlation matrix with its eigen-decomposition:
where (orthonormal eigenvectors) and .
Partition the eigenpairs into market components (hopefully justone, typically the largest eigenvalue(s)) and non-market (detoned) components.
so that
2. Remove the market (detoning)
Subtract the market part to get the detoned correlation matrix :
Because we removed at least one eigenvector, is singular (it has at least one zero eigenvalue).
Rescale to enforce unit diagonal if you need a correlation matrix:
3. Portfolio optimization in the reduced (principal-component) space
You cannot directly invert . Instead optimize on the non-zero principal components (the detoned subspace) and then map allocations back to the original assets.
Write a portfolio as a linear combination of the surviving eigenvectors:
where is the matrix of eigenvectors that survived detoning (i.e. the columns of W_D), and is the vector of allocations on those principal components.
Take the classic mean–variance objective (risk aversion ):
Substitute . Using orthonormality and the block decomposition, the objective in becomes
where is the diagonal matrix of the non-zero eigenvalues (the same as .
The first-order optimality condition yields the closed form
Finally map back to original asset weights:
Note: because W_+ columns are orthonormal, is the left-inverse of . This expression avoids inverting the full (singular) and only requires inverting the diagonal .
What is ?
So tells you how much you are investing in eigenportfolio i (the eigenportfolio built from eigenvector ).
After detoning (removing market eigenvectors), we only keep the “surviving” eigenvectors . Instead of trying to optimize in the full asset space, we solve for in the reduced space:
Then we map back to original asset weights:
This way we only allocate risk to components that carry non-noise information.
Shrinkage
Shrinkage is a technique to improve the estimation of covariance (or correlation) matrices when data is noisy or limited.
Empirical covariance matrices, estimated from historical returns, are often unstable or ill-conditioned (especially if you have many assets and few observations). So, instead of using the raw covariance matrix , combine it with a target that is more stable (like the identity matrix or an average correlation matrix).
Formally:
= shrinkage intensity.
- : no shrinkage (use raw covariance)
- : full shrinkage (use only the target)
3.Distance Metrics
Correlation
Correlation measures linear codependence but is not a metric (fails nonnegativity and triangle inequality).
We therefore need a metric that gives a geometry/topology to compare and cluster data, so define:
standardize X,Y into zero-mean, unit-variance vectors x,y.
If we look at the Euclidean distance:
it expands to:
So is proportional to a Euclidean distance, hence inherits metric properties.
since .
Positively correlated show small distance, negatively correlated
large distance.
This makes sense in long-only portfolios
(negatively correlated assets act as diversifiers).
Absolute Correlation
Sometimes, in long-short portfolios, we want negatively correlated assets to be considered similar.
So we can define absolute correlation by:
That is still a metric but highly negatively correlated assets have small distance.
Problems of Correlation
- Correlation quantifies the linear codependecyof two assets
- It’s highly influenced by outliers
- Its application beyond the multivariate Normal case is questionable (In the Gaussian world correlation is a clean, sufficient measure of dependence, outside it correlation can be unstable, incomplete, or misleading).
So better to introduce other metrics.
Entropy of a Discrete Random Variable
Shannon entropy measures the average amount of information needed to describe the outcome of a random variable or the uncertainty or diversification
For random variable with support and pmf :
with the convention that: (limit argument).
If event has probability , its “surprise” is , so low probability brings high surprise.
Entropy can be interpreted as the expected surprise: it's the average uncertainty in .
When all probability mass is on a single outcome, there's no uncertainty and . The Maximum entropy is reached when is uniform over its support and has
Joint Entropy
For random variables , with joint pmf :
It measures the uncertainty of the pair considered together.
Propertries:
(equality holds if and are independent.)
Conditional Entropy
The conditional entropy of given is:
measures the remaining uncertainty about X once Y is known.
- Conditional entropy is always ≤ entropy:
-
Knowing can never increase the uncertainty about X.
-
Equality occurs if and are independent ( gives no info about ).
-
Entropy of a variable given itself:
If you already know X, there’s no uncertainty left.
- Chain rule for entropy:
Total uncertainty about can be decomposed into uncertainty of and residual uncertainty of after knowing .
Kullback–Leibler Divergence
For two discrete probability distributions and defined on the same set :
-
= true probability of x
-
= reference or approximate probability of
-
Condition: if to avoid division by zero
-
KL divergence measures how much diverges from .
-
It quantifies the “extra information” required if we encode data using instead of the true distribution .
-
Equality occurs only when .
-
(Order matters, so KL divergence is not a metric)
-
Triangle inequality fails, so KL divergence does not satisfy all properties of a distance metric.
-
If (uniform distribution), measures how far p is from uniform.
Cross Entropy
For two discrete probability distributions (true distribution) and (approximation or model) defined on the same set :
- = true probability of outcome x
- = probability assigned by a model or reference distribution
- It measure the uncertainty of when using instead of the true .
Entropy: measures uncertainty using the true distribution.
Cross-entropy:
- Cross-entropy is always greater than or equal to true entropy.
- The difference measures how “wrong” is.
Mutual Information
Mutual information measures how much knowing one variable reduces uncertainty about another.
- = entropy of (uncertainty about )
- = conditional entropy of given Equivalently:
- Non-negative: if and are independent (knowing gives no info about )
- Symmetric:
- Upper bound:
- Not a metric: Does not satisfy triangle inequality
- Grouping / decomposition:
Mutual information can be expressed as a KL divergence:
It measures >how far the joint distribution is from independence.
4. Optimal Clustering
Clustering groups objects (items) by similarity using their features. The goal is to produce clusters where intra-cluster similarity is high and inter-cluster similarity is low. Clustering is a form of unsupervised learning because we do not provide labelled examples.
Proximity matrix
A proximity matrix measures how "close" or "similar" objects in a dataset are to each other.
- For a dataset with elements, the proximity matrix is an matrix.
- Each entry represents the closeness between object and object .
Typical definitions:
A symmetric proximity matrix with zeros on the diagonal is common when using pairwise distances.
Two main families of clustering:
Hierarchical clustering
- Produces a nested sequence of partitions (a dendrogram).
- Top: a single cluster containing all points. Bottom: each point alone.
- Two approaches:
- Agglomerative (bottom-up): start with a lot of partitions and merge.
- Divisive (top-down): start with one cluster and split.
- No need to specify up-front (but you choose a cut in the dendrogram to get clusters).
Partitional clustering
- Partitions the dataset into disjoint clusters.
- Each object belongs to exactly one cluster.
- Example: k-means, k-medoids, spectral clustering.
- Often requires the number of clusters as input.
Practical issues
- Curse of dimensionality: when the number of features is large relative to observations, distances become less informative and clustering can degrade. Dimensionality reduction (PCA, t-SNE, UMAP) or feature selection helps.
- Initialization randomness: algorithms like k-means are sensitive to initial centroids.
Because partitional methods require , several methods exist to estimate a good :
Elbow method
- Compute within-cluster sum of squared errors (WCSS) for different .
- Plot WCSS vs . The "elbow" point (where marginal gain drops) is a reasonable .
Silhouette analysis
- Measures how well each point lies within its cluster compared to the nearest other cluster.
For an observation :
- Let = average distance from to all other points in the same cluster (intra-cluster distance).
- Let = minimum over other clusters of the average distance from to points in that other cluster (nearest inter-cluster distance).
The silhouette coefficient for is
- : well clustered (close to own cluster, far from others).
- : on or near cluster boundary.
- : likely misclassified (closer to another cluster).
The average silhouette score across all points is a scalar summary used to compare different : higher is better.
Practical checklist for clustering
-
Preprocess
- Standardize / normalize features when distances are used.
- Handle missing values.
- Reduce dimensionality if needed.
-
Choose distance / similarity
- Euclidean for continuous, cosine for directional data, Jaccard for binary sets, etc.
-
Choose algorithm
- Hierarchical if you want a dendrogram and no fixed .
- K-means/k-medoids for large datasets with spherical-ish clusters.
-
Select
- Use elbow, silhouette, gap statistic, or domain knowledge.
-
Validate
- Visual inspection (2D/3D embedding).
- Cluster compactness and separation metrics (silhouette, Davies–Bouldin).
- If possible, external validation against known labels.
Once we run a clustering algorithm (e.g., k-means), we still need to evaluate how good the clustering result is.
Quality Measure
Define the overall clustering quality:
Where:
- = mean of silhouette scores (average clustering quality).
- = variance of silhouette scores (consistency across points).
Higher means better clustering (high average silhouette, low variability).
Base Clustering Algorithm
At the base level, the procedure works as follows:
-
Input
- Start from the observation (distance/similarity) matrix.
-
Outer Loop (over )
- For :
- Run k-means clustering with clusters.
- Compute the quality measure from silhouette scores.
- Store results for that .
- For :
-
Inner Loop (over initializations)
- Repeat the above with different random initializations of centroids.
- This reduces sensitivity to random starts.
-
Selection
- Choose the clustering result with the highest quality .
- This yields:
- Optimal number of clusters .
- Best initialization (most stable clustering result).
Even after selecting the best and initialization, some clusters can still be poor quality.
Reclustering Low-Quality Clusters
To refine the clustering, we recluster only the bad clusters.
-
Start with Base Clustering Result
- We already have clusters from the base algorithm.
- For each cluster , compute its quality score (mean silhouette score of its members).
-
Identify Poor-Quality Clusters
- Compute overall average quality:
- Identify clusters with → “below-average quality.”
- Let = number of such clusters.
- Decision Rule Based on
- If :
- No meaningful reclustering, so return base clustering.
- If :
- Recluster only those clusters :
- Build a new observation matrix for elements of these clusters.
- Rerun the base algorithm (search over and initializations) on this reduced subset.
- Recluster only those clusters :
-
Check Improvement
- Compare average quality before vs. after reclustering.
- If quality improved:
- Merge the unchanged good clusters with the newly reclustered clusters.
- Else:
- Keep the original base clustering result.
5. Financial Labels
Supervised learning aims to predict an output given features .
Types of Supervised Learning
-
Regression problems
- Predict a continuous target (real numbers).
- Examples drawn from infinite population (countable like integers or uncountable like reals).
-
Classification problems
- Predict a discrete label from a finite set (e.g., , ).
Fixed-Horizon Labeling
We have a feature matrix:
- For each observation :
- Let = index of bar where features are sampled.
- Define a fixed horizon .
- Compute return over horizon :
Assign label based on return:
Where:
- = constant return threshold.
- Time bars = bars sampled at regular time intervals.
- Result: fixed time horizons for all samples.
Concerns with Fixed-Horizon Labeling
- Returns show intraday volatility patterns (open/close more volatile).
- Constant transfers seasonality into labels, label distribution becomes non-stationary.
Solution: use tick/volume/dollar bars instead of time bars or standardize returns using volatility estimate:
where = predicted volatility. Then apply labeling rule to -scores.
Triple-Barrier Method
Labels should represent actual trading outcomes: profit, loss, or timeout.
This method sets three barriers:
- Upper Horizontal Barrier: Profit-taking (success).
- Lower Horizontal Barrier: Stop-loss (failure).
- Vertical Barrier: Maximum holding period (timeout).
Step-by-Step Procedure
- Start at (where features observed).
- Monitor price path forward until one barrier is hit.
- Assign label :
- If upper barrier reached first: .
- If lower barrier reached first: .
- If vertical barrier reached first:
- Option 1: (neutral).
- Option 2: (final return sign).
Trend Scanning Method
Instead of setting a fixed horizon , profit-taking, or stop-loss levels, trend scanning lets trends run naturally until they end.
Label each observation as part of:
- Uptrend:
- Downtrend:
- No trend:
Define a Trend
Fit a local linear regression over a window of observations:
- = slope, direction & strength of trend.
- = residuals (noise).
Test Statistical Significance
Compute t-statistic of the slope:
- Large : strong trend evidence.
- Near 0: no clear trend.
Assign Labels
For each :
Where = critical t-value threshold.
Meta-Labeling
Meta-labeling is a two-model approach:
- Primary model: predicts position direction (long/short).
- Secondary (meta) model: predicts whether that position will be profitable (filtering false positives).
The goal is to reduce exposure to losing trades and size positions proportionally to predicted success probability.
Expected Value & Risk
Let = probability of profit and = payoff magnitude.
The expected value is:
- : positive expected profit.
- : no edge.
Expected Variance
- Highest when (most uncertain).
- Shrinks as or (certainty increases).
Sharpe Ratio
Standardize risk/return with Sharpe-like measure:
- : attractive opportunity.
- : avoid trade.
Mapping to Position Size
Convert to position size :
Where = CDF of standard normal.
- (no trade)
- Large (max long)
- Large (max short)
Meta-Labeling for Position Size with Multiple Classifiers
Suppose we have meta-labeling classifiers:
Sum of predictions:
- Mean:
- Variance:
As , by de Moivre–Laplace :
Thus, average prediction:
Hypothesis Test
Null hypothesis: (no predictive edge)
t-statistic:
Follows Student-t distribution with d.o.f.
Mapping t to Bet Size
Convert to bet size :
Where = CDF of Student-t distribution.
- (no bet)
- Large (max long)
- Large (max short)
In practical:
- : strong long conviction → large .
- : strong short conviction → large .
- : no edge → (no position).
6. Feature Importance Analysis
P-Values (Statistical Significance)
Probability of observing the estimated coefficient if the true coefficient = 0 .
It tests whether a feature has any effect, not its predictive power.
The p-value is a probability, but not the probability that your hypothesis is true. It answers a very specific question:
“If the null hypothesis were true, how likely is it to observe a result as extreme (or more extreme) than what I actually observed?”
Limitations- False positives/negatives if model assumptions fail.
- Not robust with multicollinearity (correlated features).
- Measures statistical relevance, not:
- Effect size
- Predictive power
- Causality
A low p-value doesn't mean feature is “important”, it only means the effect is statistically detectable.
Mean Decrease Impurity (MDI) — Tree-Based Models
A clear video explanation can be found here, credits to StatQuest
- At each node pick feature and threshold to split:
- Left:
- Right:
- Measure impurity with e.g.:
- Entropy:
- Gini:
- Information gain (impurity reduction) for a split:
- Feature importance (MDI) for feature : sum of weighted over all nodes where was used.
Mean Decrease Accuracy (MDA)
This algorithm measures out-of-sample importance.
- Fit model and compute cross-validated performance (baseline).
- For each feature:
- Shuffle that feature's values (breaks relationship with target).
- Recalculate cross-validated performance.
- = performance(before shuffle) − performance(after shuffle).
- Large positive MDA means that feature important.
- MDA near zero means that feature irrelevant.
- Negative MDA means feature damaging performance (model improved after shuffling).
Model Performance Metrics
Negative Average Likelihood (NegAL)
where if observation has true label , else 0; is predicted prob.
Range:.
Higher =is better (closer to 1 the model assigns higher probability to true labels).
Probability-Weighted Accuracy (PWA)
where if prediction correct else 0; .
It weighs correct predictions by model confidence.
Feature Clustering for Importance
With highly codependent features the individual importance unreliable, so it's commonoto cluster features to analyze them better.
-
Represent features in a metric space
- Options:
- Correlation-based distances (linear dependencies).
- Information-theoretic metrics (e.g., Variation of Information) to capture nonlinear redundancies.
- Options:
-
Cluster formation
- Apply an ONC (Optimal Number of Clusters) algorithm:
- Finds number of clusters and assignments.
- Partitional assignment: each feature belongs to exactly one cluster.
- Within-cluster features share much information; across clusters share little.
- Apply an ONC (Optimal Number of Clusters) algorithm:
-
Optional residualization
- For cluster , regress each feature on features from earlier clusters :
- Replace with residuals .
- If regressors are too many, reduce dimensionality inside clusters.
- Apply MDI or MDA at the cluster level (not single-feature).
- Interpret which groups of features drive model performance.
7. Portfolio Construction
Given assets the expected excess returns (vector ) and the covariance matrix (), the goal is to find portfolio weights that minimize portfolio variance .
Classical Mean–Variance Optimization (Variance Minimization)
The vector encodes the portfolio constraint (e.g., fully invested: ).
Lagrangian:
Optimal weights:Useful Special Cases
- Equal weights under isotropic variance: ,
- Inverse-variance : diagonal,
- Minimum-variance: ,
- Maximum Sharpe : ,
Numerical Stability & Conditioning Problem
Let be the standardized correlation matrix of . The solution needs to calculate on .
If assets are highly correlated (), then is ill-conditioned:
- Condition number large means that numerically unstable (small errors in estimate produce large swings in ). We need Markowitz when correlations exist, but those same correlations make the solution unstable.
Practical fixes :
- Shrinkage estimators (Ledoit–Wolf)
- Factor models (lower-dimensional structure)
- Regularization: add to before inversion ()
- Robust/resampled optimization, constraints on weights (box, turnover), or use of priors (Black–Litterman)
Nested Clustered Optimization (NCO)
The goal is tos tabilize Markowitz by solving smaller, better-conditioned subproblems.
- Cluster the correlation matrix to find groups of highly correlated assets.
- Intracluster optimization:
- For each cluster, compute intracluster weights using the denoised covariance (call it
cov1). - Smaller cluster size means better-conditioned covariance estimates.
- With very correlated cluster, the min-variance tends toward equal weights, so instability is limited.
- For each cluster, compute intracluster weights using the denoised covariance (call it
- Intercluster optimization :
- Build reduced covariance (
cov2) between clusters. cov2is by construction close to diagonal; invertibility and conditioning are much improved.
- Build reduced covariance (
- Combine:
- Final asset weights = (intra-cluster weights) × (inter-cluster weights).
- Dimensionality reduction: each inversion is on smaller matrices.
- Denoising at step 1 reduces noisy eigenvalues.
- Aggregation produces a near-diagonal inter-cluster covariance, improving stability.
8. Testing Set Overfitting
Selection Bias under Multiple Testing (SBuMT)
SBuMT occurs when a researcher tests many strategies on the same historical dataset and then reports only the best-performing one.
This process leads to false discoveries , strategies that look profitable in-sample but fail in live trading.
True vs. False Investment Strategies & Precision/Recall
The total number of strategies is
where:
- = number of true strategies (positive expected return)
- = number of false strategies (zero or negative expected return)
The Odds ratio of true to false strategies is:
In finance, signal-to-noise ratio is usually very low, meaning most strategies are false.
So the number of true strategies is:
and the number of false ones:
Statistical Errors
-
False Positive Rate (Type I error):
- False Positives (FP):
- True Negatives (TN):
-
False Negative Rate (Type II error):
- False Negatives (FN):
- True Positives (TP):
The Precision (Positive Predictive Value) is defined as:
and the Recall (Sensitivity) as:
Precision strongly depends on odds ratio θ.
A discovered strategy is more likely to be false than true if:
Type Error Across Multiple Trials
(False alarm: see a signal where none exists, identify a false positive)
In a single trial :
- (Type I error) =
- (No Type I error) =
with K independent trials:
- (No Type I error in any trial):
- (At least one Type I error) = Family-Wise Error Rate (FWER):
FWER increases with K , the more strategies you test, the higher the chance of finding a false positive.
Type Error Across Multiple Trials
(Missed discovery: fail to detect a true strategy)
In a single trial::
- (Type II error) =
with K trialsP(Missing all positives):
- (Type II error)
As :
- (false positive risk grows)
- (less likely to miss all true positives)
Precision & Recall Adjusted for Multiple Testing
The Adjusted Precision can be defined as:
and the Adjusted Recall as:
As increases:
- Recall improves (lower chance of missing all true strategies).
- Precision usually drops (higher risk of including false positives).
The Sharpe Ratio Framework
Given the strategy excess returns:
and the Population (true) Sharpe Ratio:
The Sample (estimated) Sharpe Ratio is defined as:
where is sample mean return, sample standard deviation.
The distribution of Sample SR can be defined as following.
Case 1: IID Normal Returns
Case 2: Non-Normal Returns
Empirical evidence: hedge fund returns often exhibit:
- Negative skewness
- Positive excess kurtosis
where:
- = skewness
- = kurtosis
Special case: for Normal returns (), we recover the initial formula.
SBuMT and Maximum Sharpe Ratios
Given independent strategies with Sharpe ratios:
the Expected Maximum of K Sharpe Ratios
where:
- = quantile function of standard Normal
- = Euler–Mascheroni constant
The more strategies you try (), the higher the expected maximum Sharpe ratio by chance.
So a discovered strategy is likely a false positive unless:
Deflated Sharpe Ratio (DSR)
Adjusts Sharpe ratio for:
- Multiple testing ()
- Sample size ()
- Skewness () and kurtosis ()
A high DSR brings stronger evidence of true profitability. A low DSR means thatis likely a false discovery
Clustering Strategies & Cluster-Level Returns
N strategies are grouped into clusters based on correlations, so it's possible to reduces dimensionality for multiple testing bias.
The aggregate return series for each cluster is:
Weights chosen to minimize cluster variance:
where:
- = covariance matrix of returns within cluster
- = vector of ones of appropriate size
Clustering reduces effective number of trials :
- Lowers false discovery probability
- Produces a more realistic null distribution
- Improves precision of DSR-based significance testing