Mi è sempre piaciuto prendere appunti, tenere traccia di ciò che studio e archiviare tutto quello che leggo. Fino a qualche anno fa, tutto questo si riduceva a quaderni di appunti puliti, precisi e in una libreria ordinata. Crescendo, ho gradualmente abbandonato carta e penna e, da quando ho comprato un iPad,mi sono convertito totalmente al digitale.
Questo grande cambiamento, oltre a farmi risparmiare tempo e denaro in cartoleria, mi ha forzato a ripensare completamente il modo in cui gestisco la mia conoscenza. Per un periodo di transizione sono stato grande utilizzatore di Notion, integrando tutto ciò che potevo (budgeting, calendario, appunti, diario ecc...) in un'unica soluzione.
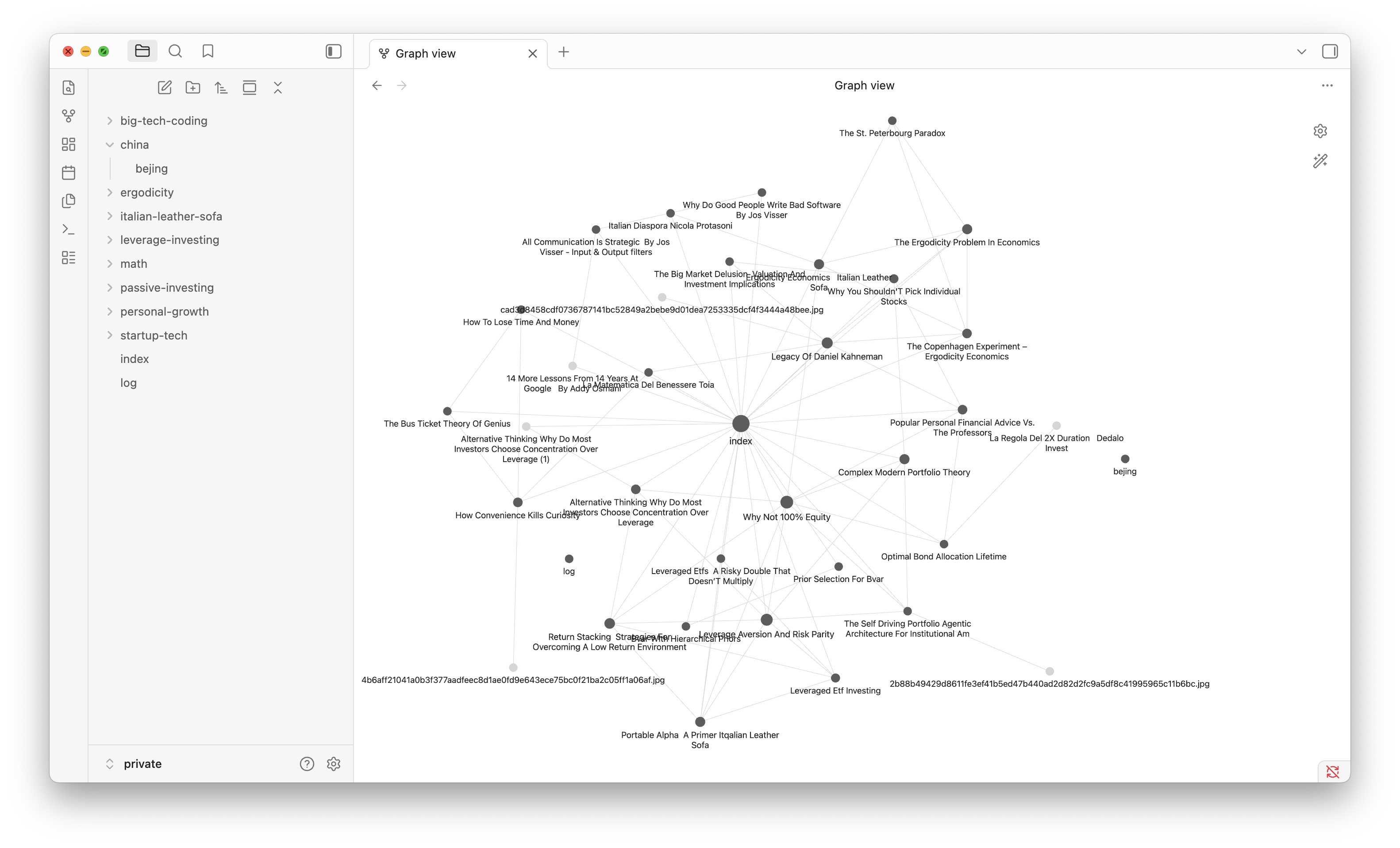
Solo in seguito, rendendomi conto dei limiti tecnici di quella piattaforma, ho optato per soluzioni ad hoc molto più flessibili, in modo da avere pieno controllo di ogni cosa. Di conseguenza, se tutto ciò che riguarda i soldi è gestito indipendentemente in Google Sheet, tutti i miei appunti sono attualmente archiviati e gestiti in un'unica repository che, curiosamente, contiene anche il codice sorgente di questo sito.
Esattamente come mi piaceva l'idea di avere tutto in Notion, ho cercato di replicare questa centralizzazione in modo molto più custom, con una struttura modulare che mi permettesse, allo stesso tempo, di:
- mantenere il mio blog/sito personale
- archiviare gli appunti universitari disponibili in
/notes - archiviare e modificare i miei appunti privati, non direttamente consultabili online
- fungere da vault per Obsidian, per una migliore visualizzazione nel quotidiano
- interagire con un LLM (che chiameremo JackGPT!), sia in locale da VS Code che online su
/ask, che risponda sulla base di tutta la mia conoscenza e sia sempre aggiornato con il contesto.
Nelle righe successive cercherò di dare una visione ad alto livello della struttura del progetto e delle motivazioni dietro ogni scelta. I dettagli tecnici di implementazione sono facilmente consultabili alla pagina GitHub del progetto o interpellando direttamente JackGPT.
Quanto sei disposto a faticare per aprire un libro?
Come ampiamente discusso in un recente blog post, voglio ancora mantenere il più possibile il controllo di questo sito e, in maniera più ampia, della mia conoscenza, motivo per cui il supporto dell'AI è circoscritto esclusivamente a task operative che non interferiscono troppo con tutto ciò che riguarda la lettura, la rielaborazione e lo studio di un contenuto.
Sono infatti convinto che alcune fatiche e alcuni attriti durante il processo di apprendimento siano propedeutici e formativi mentre, al contrario, alcune attività puramente operative (correzione grammatica, sintassi, formattazione, organizzazione delle cartelle ecc.) siano una pura perdita di tempo ed energia.
Come disse il saggio, "spendere del tempo per sfogliare e consultare un libro in biblioteca può essere formativo, ma doversi fare 100 km a piedi per raggiungerla no".
Secondariamente, date capacità di LLM "onniscenti", questa struttura mi permette di approfondire e studiare argomenti che difficilmente avrei affrontato in "solitaria".

L’informazione non è conoscenza (Albert Einstein)
Negli ultimi mesi, mi sono infatti reso conto di star "processando" tanta informazione, tramite articoli, incontri, deep dive con Gemini, papers, libri etc... in maniera più o meno approfondita, senza però tenere traccia in maniera utile di tutta la conoscenza a cui esposto. Di conseguenza, costruire una struttura e delle procedure attorno a ciò, nonostante richieda un minimo di fatica in più nel quotidiano, penso che, nel lungo termine, sia in grado di ritornare utile e soprattutto permettermi, nel caso ce ne sia bisogno, di ripassare, integrare o collegare più facilmente gli argomenti.
Nonostante l'ampio utilizzo dell'ai in questa repo (sia per lo sviluppo che per il mantenimento degli articoli), ogni appunto nasce "AI-free", i.e. da un interesse personale, da un articolo originale scritto da terzi o da qualche riga scritta "manualmente". L'intervento dell'AI resta infatti di puro supporto e avviene in un secondo momento, quando la direzione del deep dive è già tracciata nella mia testa.
In sintesi, non nego che utlizzare l'intelligenza artificiale a disposizione è stato fondamentale: nonostante non abbia una formazione informatica, poter lavorare con con Claude mi ha permesso, dopo una fase di progettazione ad alto livello, di scrivere e revisionare tutto il codice in poco tempo.

Il punto di partenza di tutto è stata la directory del codice sorgente di questo sito, nulla di troppo complicato: un'app in Next.js in cui, nella cartella wiki/public, sono solito scrivere gli articoli del mio blog e i miei appunti universitari, entrambi in formato .md/.mdx e il cui contenuto resta AI-free.
Il primo passo fondamentale è stato modificare la struttura del progetto in modo da aggiungere anche tutte le note "private", ossia tutto ciò che leggo, appunto o trascrivo e che non voglio finisca online, tra cui rientrano gli articoli e i paper che leggo per interesse personale. Fino a qualche tempo fa, ogni volta che leggevo contenuti di mio interesse, scaricavo in locale un PDF, per non essere dipendente da un link su Google o correre il rischio che il contenuto venga modificato o, peggio, eliminato.
Attualmente, al contrario, questa funzione di archivio è pienamente integrata nel progetto. Dopo aver salvato tutto ciò che è di mio interesse nella cartella wiki/source, avvio da terminale una pipeline che esegue in locale MinerU, il quale converte il documento di input in Markdown, estrae eventuali immagini e le salva nella directory di output. La pipeline scrive successivamente il file risultante sotto wiki/private/<topic>/title.md e copia le immagini in wiki/private/<topic>/images.
Dopo l'estrazione, la stessa pipeline, tramite chiamata API, si affida un LLM in due passaggi: prima per inferire un topic breve, poi per pulire e normalizzare il Markdown.
Nonostante i file privati non vengano pubblicati online, a build time uno script scansiona wiki/public e wiki/private, pulisce il testo e, sempre tramite chiamata API, crea anche gli embeddings per ogni file.
Similmente, ogni volta che prendo appunti io stesso creo, direttamente da VS Code o Obsidian, un file .md e, in caso di necessità, mi faccio aiutare da un LLM per svolgere alcune delle task menzionate.
Il risultato di tutto ciò è che, invece di avere le fonti in formati diversi e senza una struttura, tale architettura basata su file .md mi permette di modificare, integrare o pulire più facilmente tutto, integrando anche una parte più "attiva" e interattiva nel processo intellettuale.
Nonostante possa sembrare poco conveniente, mi trovo molto bene a gestire tutto il folder principalmente da VS Code, nonostante la maggior parte delle volte non debba scrivere codice, avendo accesso ai file raw e soprattutto, tramite Copilot o Claude Code, potendo interagire con un'AI che abbia sempre il contesto adeguato invece di affidarmi a un generico LLM online in cui, per quanto si possa essere precisi con un system prompt, risulterà spesso troppo generico e non adeguato alle proprie necessità.
In questo modo, inoltre, nonostante ci sia un'AI di mezzo, mi sembra di poter mantenere molto facilmente il controllo della mia conoscenza senza delegare tutto ma, allo stesso tempo, sfruttare i vantaggi e le potenzialità di questi strumenti.

Come vive JackGPT
On top of that, più per divertimento e con l'unico scopo di rendere, almeno in via indiretta, tutti i miei appunti accessibili online, ho costruito JackGPT (crediti per il nome: i miei amici di Milano che mi prendono per il culo), un minimale chatbot che risponde sulla base degli appunti più rilevanti rispetto alla query dell'utente.
Data infatti una domanda in input, il backend combina BM25 e gli embedding precedentemente creati tramite cosine similarity e una successiva Reciprocal Rank Fusion per trovare gli file più rilevanti. Questi sono successivamente allegati alla query dell'utente che, assieme al system prompt da me definito, costituiscono l'input finale per JackGPT.
(Per quanto riguarda l'API: mi sto attualmente affidando a dei crediti di OpenAI, ma non mi dispiacerebbe in futuro provare DeepSeek, qualche altro modello open o, never say never, hostare qualcosa in locale).
Come crescerà JackGPT?
Attualmente (Jun 27) JackGPT è ancora in fase primordiale e mi rendo conto non sia all'altezza dei modelli di frontiera ma, per questioni di tempo e economie di API, questa soluzione iniziale mi permette sperimentare e capire come muovermi in futuro.
Non nego infatti che ho in testa molteplici aggiornamenti e potenziali espansioni del progetto.
In primis, non mi dispiacerebbe creare una repository più "standardizzato" e indipendente dal mio sito, in modo da permettere a chiunque di clonare la repo e poter "hostare" questo knowledge management system sulla propria macchina.
Secondariamente, vorrei capire come rendere JackGPT maggiormente integrato con le mie note e più utile nel quotidiano, costruendo skill utili pur mantenendo il pieno controllo "intellettuale" degli argomenti.
In extremis, sono convinto che il "successo" di questo progetto, inteso come il livello in cui riesco a sfruttarlo per gestire meglio la mia "conoscenza", emerga nel lungo termine, quando gli appunti si accumulano, i file si intrecciano e le necessità di consultarli aumentano.
